







-
胸径和树高是林业调查的重要因子,胸径通常易测且结果精准,但树高的测量往往低效费时,结果偏差相对较大[1]。因此,为了更加方便准确地获得林木树高,李春明等[2]通过非线性混合效应模型很好地模拟了栓皮栎Quercus variabilis树高与胸径的关系;张连金等[3]通过幂函数模拟了12种不同林分的胸径与树高关系;CHAI等[4]选取常用的16个林业模型对贵州省平坝区柳杉Cryptomeria fortunei人工林树高-胸径进行拟合,选出了拟合精度相对较高的3个模型。此类研究通常需要从常用的生长模型或其扩展模型中选出很多模型作为候选模型,再对它们分别进行拟合,通过一系列的模型评价指标对其进行筛选,再结合树种生物学特性及模型的适用性选择出表现最好的模型。然而候选模型的种类和数量常常因人而异,少则几种[5-6],多则有几十种[7],过少则精度不佳,过多则计算量大,费时费力。但是,林木的生长过程复杂,导致传统的模型难以达到较高的预测精度。人工神经网络不依赖现存模型,可以最大限度地逼近任意非线性变化趋势。BP(back propagation)神经网络也称误差反向传播网络,在很多领域均有应用,是当前应用最广的神经网络模型之一,也是林业研究中常用的模型。在林业调查中,通过建立树高-胸径的关系模型来预测树高往往具有事半功倍的效果,同时在林木生长预测、生物量的估计,森林资源的监测与评价中具有较高的使用价值[4]。刘鑫等[8]、董云飞等[9]运用BP神经网络分别拟合了天然云冷杉Abies fabri针阔混交林和杉木Cunninghamia lanceolata的树高曲线,表明BP神经网络有操作简单、拟合精度高、泛化能力强等特点。目前以BP神经网络预测树高的研究主要集中于长白山落叶松Larix olgensis[10]、油松Pinus tabuliformis[11]、兴安落叶松Larix gmelinii[12]等树种构成的林分。马尾松Pinus massoniana作为南方主要用材树种,由于经营不及时、地理环境特殊等原因,大面积马尾松人工林林分结构不合理等[13-16],并且对其树高模型预测方面的研究还较少。基于此,本研究以黔中马尾松人工林为对象,通过胸径-树高建立BP神经网络,并与6个候选模型中筛选出的最佳模型进行比较,探究模型在马尾松人工林树高预测中的表现和适用性,以期为马尾松人工林树高估测及森林资源的监测与评价提供理论依据。
-
研究区(26°10′~27°21′N,106°59′~107°16′E)位于黔中息烽县、开阳县、乌当区、龙里县、平坝区5个县(区),该区地貌类型复杂多样,按形态划分为山地、丘陵和坝地三大类型;地势起伏较大,大致呈东西向延展,西部、南部较高,东部、北部较低,地形坡度大多都在25°以下;平均海拔1 200 m左右,属于亚热带湿润温和型气候,年均气温15.3 ℃,年均降水量1 200 mm;森林土壤主要有黄壤、石灰土和紫色土。黄壤为地带性土壤,一般土层较深厚。常见乔木主要有马尾松、枫香Liquidambar formosana、华山松Pinus armandii、柳杉、楸树Catalpa bungei、梓树Catalpa ovata、亮叶桦Betula luminifera、白栎Quercus fabri、麻栎Quercus acutissima等。
-
数据来源于5个黔中县(区)马尾松可持续经营试点区域经营对照样地,起源为人工林,未实施过任何经营措施,且人为干扰相对较小。其中,样地数为息烽县4个,开阳县8个,乌当区22个,龙里县16个,平坝区32个,样地大小为25 m×25 m,调查林分基本情况(坡向、坡位、海拔、郁闭度等),对样地中胸径大于5 cm的林木进行每木检尺并通过网格计算其相对位置,记录因子有树高、胸径、冠幅、第一活枝高、林木质量、相对位置,在样地的4个角及中间设置5个5 m×5 m的样方,记录主要灌木的平均高度、地径、株数、冠幅、盖度,同时设置5个1 m×1 m的的样方,记录主要草本的平均高度、盖度。
-
基于胸径-树高散点图(图1)进行模型拟合,其中,训练数据3 430株,验证数据854株。基于模型的数学特性及模型参数的生物学意义,选择常用的6个非线性生长模型(表1)。
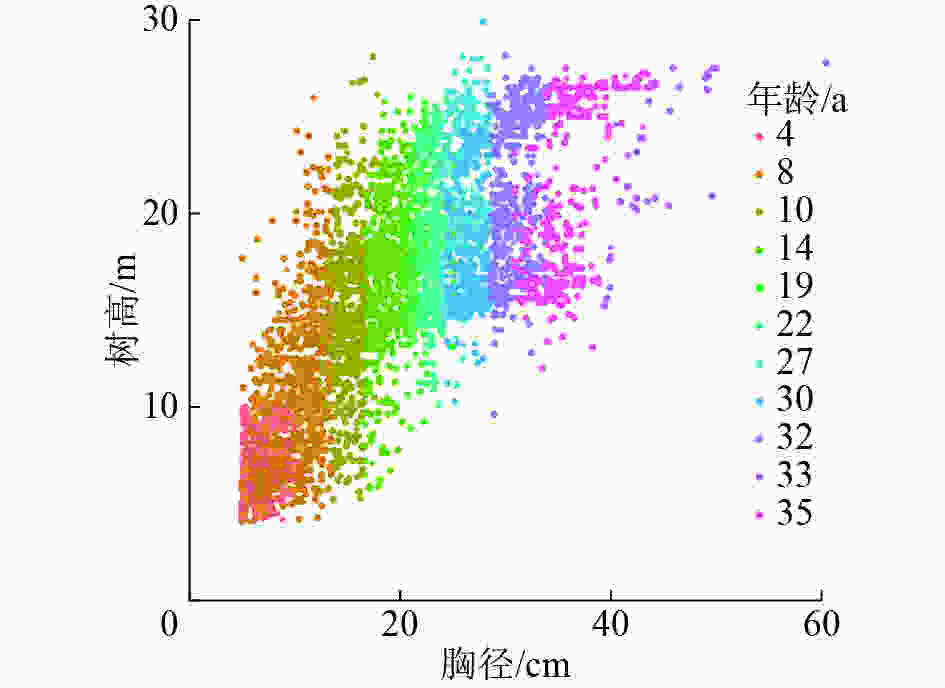
Figure 1. Diameter-height scatter diagram for model fitting data for P. massoniana
模型名称 参数/个 表达式 参考文献 Näslund 2 ${H\left( D \right) = 1.3 + \dfrac{{{D^2}}}{{{{\left( {aD + b} \right)}^2}}}}$ [17] Curtis 2 ${H\left( D \right) = 1.3 + \dfrac{{aD}}{{{{\left( {1 + D} \right)}^b}}}}$ [18] Logistic 3 ${H\left( D \right) = 1.3 + \dfrac{a}{{1 + b{\rm{exp}}\left( { - cD} \right)}}}$ [19] Weibull 3 ${H\left( D \right) = 1.3 + a\left[ {1 - {\rm{exp}}\left( { - b{D^c}} \right)} \right]}$ [20] Gomperz 3 ${H\left( D \right) = 1.3 + a{\rm{exp}}\left[ { - b{\rm{exp}}\left( { - cD} \right)} \right]}$ [21] Korf 3 ${H\left( D \right) = 1.3 + a{\rm{exp}}\left( { - b{D^{ - c}}} \right)}$ [22] 说明:H表示树高;D表示胸径;a,b,c为模型参数 Table 1. Nonliner diameter-height growth models selected for use
-
这是多层前馈神经网络的一种,其特点为:信号向前传播,误差反向传播(图2)。过程主要分为2个阶段:第1阶段是信号向前传播,由输入层经过一到多个的隐藏层,最后到达输出层;第2阶段是误差反向传播的过程,从输出层到隐藏层,再到输入层,根据误差调节隐藏层到输出层的权重和偏置,直到达到目标误差限或预设训练次数为止。神经网络的基本组成单元见图3,x1~xn(1,2,3,
$\cdots $ ,n)为神经元的输入信号,ω1~ωn(1,2,3,$\cdots $ ,n)为权重,b为偏置,∑为求和节点,σ为激活函数。根据Kolmog-orov定理,单隐层的BP神经网络就可以无限逼近任意连续的非线性曲线[16]。但过分拟合会导致模型的泛化能力差,所以在实际的应用中还要结合样本本身的特性来控制拟合程度。
Figure 2. BP neural network structure
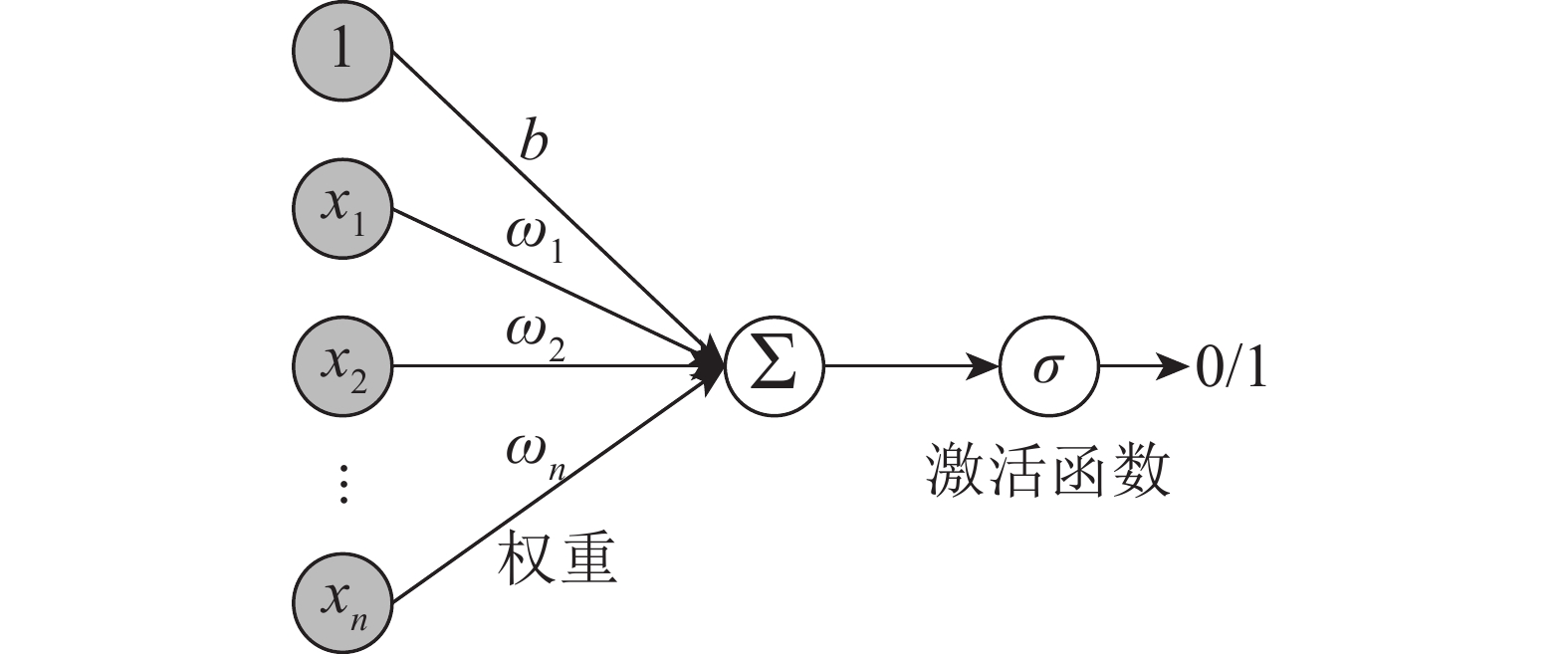
Figure 3. BP neural structure
-
基于Matlab(2016a)软件自带工具箱nntool,建立单隐层的BP神经网络以估测树高,以输入层为胸径,以输出层为树高。根据BP神经网络的隐层节点数可用
${N_h} = $ $\sqrt {{N_{{\rm{in}}}} + {N_{{\rm{out}}}}} + h$ ,其中:Nh为隐层节点数,Nin为输入层节点数,Nout为输出层节点数,h为1~10的整数[23]。本研究通过在范围内逐个测试,对比其估测精确度及泛化能力以确定最佳隐层节点数。建模时,设置目标精度为0.001,最大迭代次数为1 000,学习率为0.01,因胸径-树高关系曲线形似“高关型曲线”,所以以sigmoid(logsig)函数为隐层传递函数,以purelin函数输出层传递函数,Levenberg-Marquardt算法相对其他算法有缩短训练时间的特点,因此以Levenberg-Marquardt算法为模型训练算法。 -
对胸径-树高模型的选择通过决定系数(R2)、相对平均绝对误差(RMA)、均方根误差(RMSE)和Akaike信息准则(AIC)评价模型的拟合效果(表2),R2越大、RMA越小、RMSE越小、AIC越小,模型的拟合精度越高。
评价指标 表达式 决定系数(R2) ${{R^2} = 1 - \dfrac{{\mathop \sum \limits_{i = 1}^n {{({H_i} - \widehat {{H_i}})}^2}}}{{\mathop \sum \limits_{i = 1}^n {{({H_i} - \overline {{H_i}} )}^2}}}\dfrac{{n - 1}}{{n - p - 1}}}$ 相对平均绝对误差(RMA) ${ {R_{\rm{MA} } } = \displaystyle{\mathop \sum \limits_{i = 1}^n \left| {\dfrac{ {\left( { {H_i} - \widehat { {H_i} } } \right)} }{ {\widehat { {H_i} } } }} \right|}\Big/{n} \times 100\% }$ 均方根误差(RMSE) ${{R_{\rm{MSE}}} = \sqrt {\dfrac{{\mathop \sum \limits_{i = 1}^n {{({H_i} - \widehat {{H_i}})}^2}}}{{n - p}}}} $ Akaike信息准则(AIC) ${{A_{\rm{IC}}} = n \times {\rm{ln}} {R_{\rm{MSE}}} + 2p}$ 说明:Hi表示树高实测值;${\widehat {{H_i}}}$表示树高预测值;${\overline {{H_i}}} $表示 树高平均值;n表示样本量;p表示模型参数数量 Table 2. Model performance criteria selected for this study
-
数据统计使用Excel 2016,BP神经网络的构建及拟合使用Matlab(2016a)软件自带工具箱nntool,70%为训练数据,15%为验证数据,15%为测试数据;传统的胸径-树高模型的拟合主要使用R语言sampling程序包进行分层抽样,抽取80%为训练数据,20%为检测数据,借助lmfor程序包进行模型拟合,ggplot2程序包作图。
-
所选样地马尾松平均年龄为18 a,胸径为5.0~60.4 cm,树高为4.1~29.9 m(表3)。训练数据包括3 430株林木,胸径为5.0~50.0 cm,树高为4.1~29.9 m,覆盖了整个径阶和树高范围。测试数据包括854株林木,胸径为5.0~60.4 cm,树高为4.1~27.8 m,基本覆盖所有径阶和树高范围,说明分层抽样的可靠性。
径阶/cm 株数/株 胸径/cm 树高/m 平均值 标准差 最大值 最小值 平均值 标准差 最大值 最小值 6 370 5.9 0.6 6.9 5.0 7.1 2.2 18.7 4.0 8 345 7.9 0.6 8.9 7.0 8.4 2.5 19.6 4.2 10 300 9.9 0.6 10.9 9.0 9.8 3.1 24.3 4.2 12 294 11.9 0.6 12.9 11.0 12.4 4.0 26.0 4.3 14 297 14.0 0.6 14.9 13.0 14.4 3.9 24.3 5.2 16 275 15.9 0.6 16.9 15.0 15.3 4.0 26.9 5.3 18 289 18.0 0.6 18.9 17.0 16.8 4.0 28.1 5.8 20 257 20.0 0.6 20.9 19.0 18.0 3.3 25.3 6.7 22 312 22.0 0.6 22.9 21.0 18.7 3.4 26.0 8.9 24 314 23.9 0.6 24.9 23.0 19.2 3.6 26.3 10.1 26 287 26.0 0.6 26.9 25.0 19.7 3.7 28.1 10.3 28 228 27.9 0.6 28.9 27.0 20.0 3.8 29.9 9.6 30 205 29.9 0.6 30.9 29.0 20.3 3.5 28.2 13.3 32 181 31.9 0.6 32.9 31.0 21.1 3.9 27.5 12.8 34 132 33.9 0.6 34.9 33.0 20.6 4.0 27.0 12.0 36 90 35.8 0.6 36.9 35.0 21.5 4.4 27.5 13.6 38 43 37.8 0.6 38.9 37.0 22.2 4.3 27.0 13.1 40 33 40.0 0.6 40.9 39.0 24.0 3.8 27.0 15.2 42 30 42.0 0.6 42.9 41.0 25.1 2.5 27.3 20.2 44 15 43.6 0.4 44.3 43.0 25.6 2.2 27.3 20.6 46 4 45.9 0.5 46.5 45.5 24.9 3.2 27.5 20.4 50 8 49.4 0.4 50.0 49.0 26.3 2.2 27.5 20.9 60 1 60.4 − 60.4 60.4 27.8 − 27.8 27.8 训练数据 3 430 19.5 9.3 50.0 5.0 15.9 6.0 29.9 4.1 验证数据 854 19.3 9.3 60.4 5.0 15.7 6.0 27.8 4.1 说明:“−”表示空值 Table 3. Summary statis for all sampled trees and trees used for model calibration and validation
-
所有的模型拟合都是基于3 430株林木的胸径,拟合结果如图4所示。整体来看,Logistic模型拟合效果最差,对于胸径较小和中等(5.0~25.0 cm)的林木,除Logistic模型外,其他模型的拟合效果都比较好;对于胸径较大的林木,由于林木树高分化严重,所以6个模型拟合效果都不是很好。
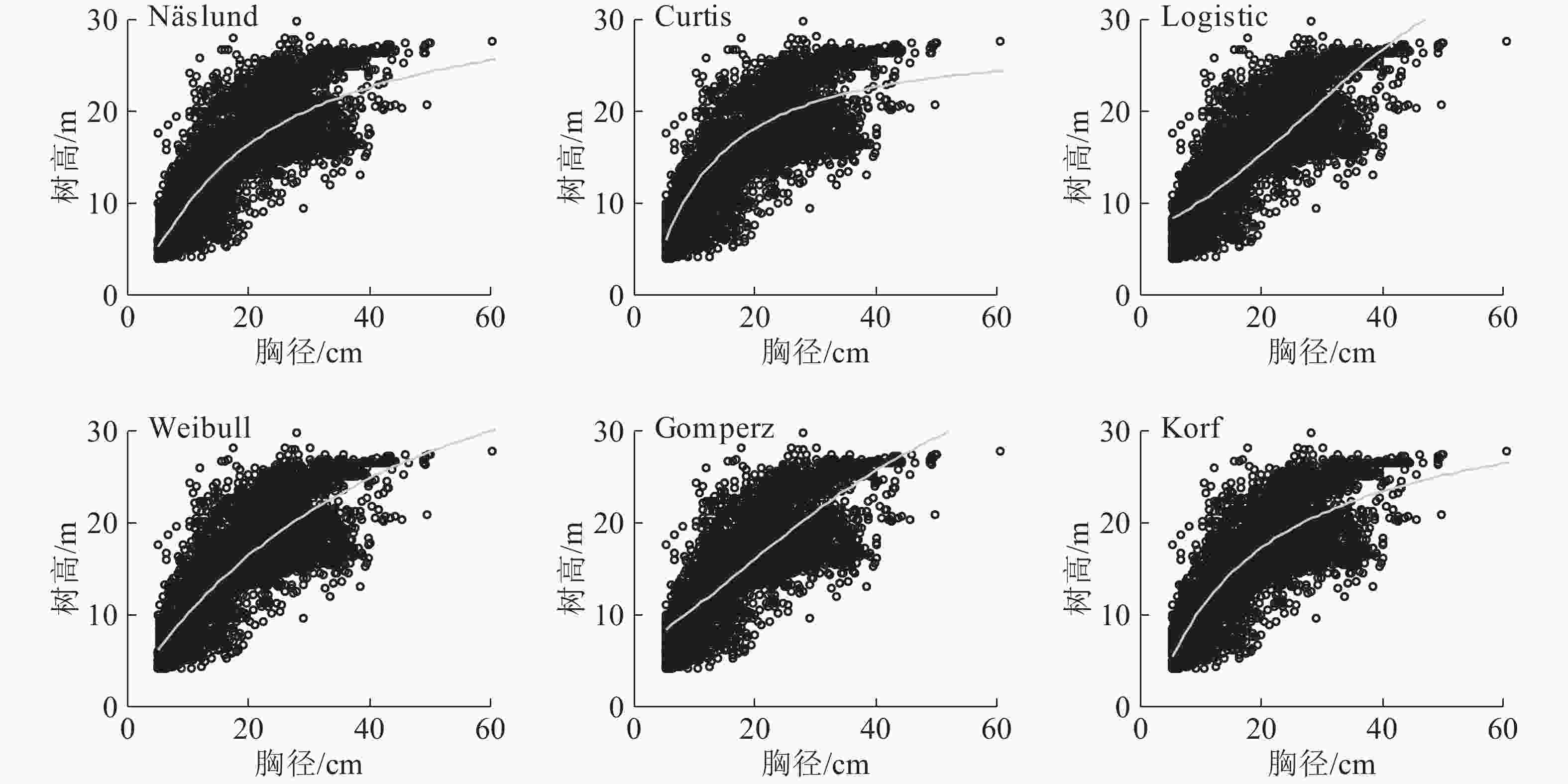
Figure 4. Six nonliner diamerter-height cureves for a P. massoniana plantation
从6个非线性模型中选择出对马尾松胸径-树高关系拟合效果最佳的模型,拟合结果如表4所示。由表4可知:除了Logistic模型外,其他模型拟合效果都较好,R2最小值为0.568,R2从小到大依次为Logistic模型、Gomperz模型、Curtis模型、Weibull模型、Näslund模型、Korf模型,RMSE从大到小依次为Logistic模型、Gomperz模型、Curtis模型、Weibull模型、Korf模型;RMSE最大值仅为4.218。综合考虑4个评价标准,Korf模型拟合效果最佳。
模型 a b c 训练样本 验证样本 R2 RMA/% RMSE AIC R2 RMA/% RMSE AIC Näslund 1.614 0.176 − 0.635 25.018 4.044 23 176.40 0.623 20.089 3.630 4 626.377 Curtis 27.15 9.538 − 0.626 23.808 4.094 23 282.51 0.622 18.645 3.634 4 628.369 Logistic 37.18 5.804 0.064 0.568 27.210 4.402 23 903.70 0.551 21.652 3.963 4 777.537 Weibull 37.18 0.031 0.941 0.629 24.640 4.079 23 252.32 0.615 19.600 3.671 4 646.573 Gomperz 37.18 2.016 0.039 0.603 25.797 4.218 23 538.00 0.589 20.493 3.790 4 701.199 Korf 37.18 6.796 0.698 0.650 23.585 3.963 23 003.99 0.641 18.877 3.545 4 587.180 说明:“−”表示空值 Table 4. Parmeter estimates and performance criteria of 6 nonlinear meight-diameter models for a P. massoniana plantation
-
用于模型测试的林木854株,胸径(5.0~60.4 cm)。由表4可知:表现最佳的是Korf模型,检测样本的模型拟合结果与训练样本一致,Korf模型和Näslund模型能够较好地预测林木树高,可选取这2个模型作为研究区马尾松人工林胸径-树高预测模型。此外,由于Korf模型为3参数模型,较2参数模型复杂,但是当研究区大、样本较复杂时有较好的拟合效果,而2参数模型较适合于小面积、数据量较小的情况。因此,选用Korf模型为最佳的胸径-树高模型。
-
以胸径为输入变量,以树高为输出变量,建立隐层为Nh的BP神经网络。根据经验公式求得隐层数为2.414~11.414,由于神经网络训练结果有一定的波动,为增加模型的容错率,一次将隐层数设置为2~11的整数,每个节点数训练10次并计算R2和RMSE的平均值(表5),随着隐层节点数的增加,所有数据RMSE最大仅为3.742,大部分R2都大于0.700,但在测试数据中存在R2小于0.700的情况。对于训练数据和验证数据,随着隐层节点的增大,R2也逐渐增大,RMSE对于训练数据和验证数据的变化情况与R2相同,随着隐层节点数的增加逐渐减小;对于测试数据,因为是独立验证样本,未参与建模,所以测试数据的R2和RMSE上下波动,最大和最小分别为0.717和3.513。
节点数 决定系数R2 均方根误差RMSE 训练
数据验证
数据测试
数据训练
数据验证
数据测试
数据2 0.712 0.717 0.717 3.546 3.655 3.513 3 0.713 0.713 0.709 3.535 3.643 3.554 4 0.714 0.714 0.695 3.527 3.564 3.554 5 0.715 0.714 0.695 3.346 3.512 3.645 6 0.722 0.720 0.703 3.335 3.412 3.616 7 0.724 0.721 0.710 3.310 3.345 3.598 8 0.726 0.726 0.708 3.282 3.312 3.612 9 0.726 0.726 0.705 3.256 3.245 3.721 10 0.728 0.728 0.709 3.238 3.231 3.645 11 0.729 0.729 0.701 3.234 3.203 3.742 Table 5. Average statistics of fitting with different hidden layers for 10 times
对于测试数据,随着隐层数的增加,预测精度未得到明显提升。为进一步确定隐层节点数量,将神经网络的预测树高与对应的胸径建立散点图,当数据出现过拟合时说明该隐层节点数已不可取。从图5可见:从节点数为3开始就出现了分化及变形,所以确定此时已经出现过拟合的情况。考虑到模型的实用性及马尾松的生物学特性,故选择图像出现过拟合时隐层节点数的前一个节点数作为最佳隐层节点数,即最佳隐层节点数为2。
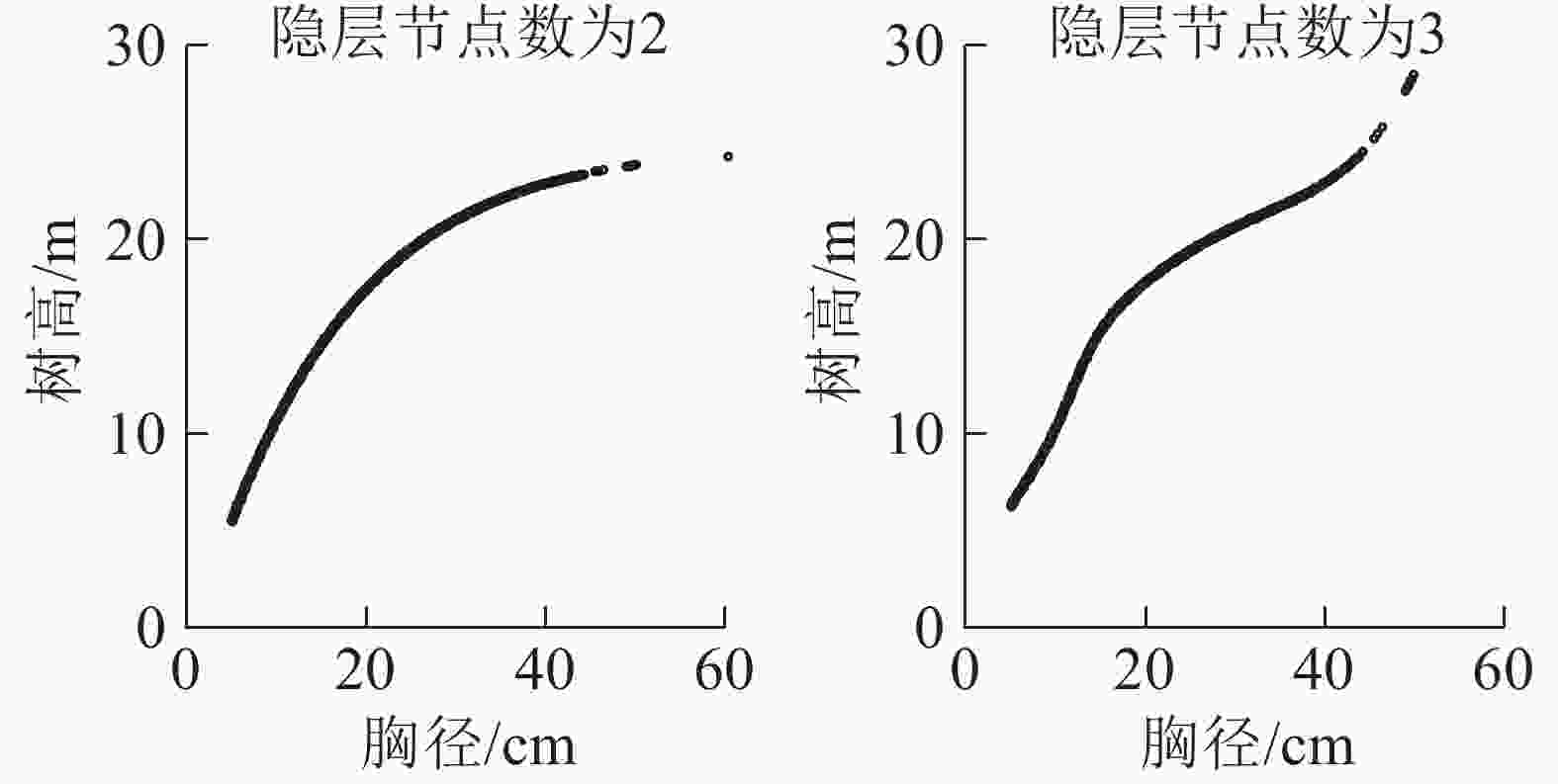
Figure 5. Diameter-height scatter diagram for over-fitting
-
确定最佳隐层节点数后,在同一个隐层节点数的基础上不断训练模型,最终选择合适的结构[输入层节点数(Nin)∶隐层节点数(Nh)∶输出层节点数(Nout)=1∶2∶1]为最后的模型,经训练得到的传递函数模型:h1=logsig(2.580 6+0.510 32D);h2=logsig(1.614 1+1.512 8D);H=purelin(1.111+2.155 1h1+1.403 5h2)。其中:hi为隐层神经元的输出,i=1,2;D为胸径;purelin为线性函数;logsig为对数S型函数;H为树高。
-
运用6个广义非线性模型(表4)与BP神经网络(表5)对82块样地的抽样数据对比发现:广义非线性模型的R2均为0.500~0.700,RMSE最小为3.963;而BP神经网络训练数据、验证数据、测试数据的R2均大于0.700,RMSE最大仅为3.742,优于广义非线性模型的最大值。因此,在马尾松胸径-树高建模方面,BP神经网络模型比广义非线性模型效果好。
-
在研究胸径-树高的关系时,模型选择不但要考虑模型的性能及拟合精度,还需考虑其生物学意义[24]。尽管所有模型都具有较好的拟合效果,但是Weibull、Näslund、Korf、Gomperz、Curtis这5个模型对马尾松人工林胸径-树高关系拟合的效果相近,均具有较高的R2和较低的RMA、RMSE、AIC。与此前的大部分研究结果相似[25-27],CHAI等[4]表明:Weibull和Näslund模型的拟合精度最高。SHARMA等[28]通过对挪威云杉Picea abies胸径-树高关系的拟合也发现:Weibull模型有较好的拟合精度。这可能是因为这几个模型具有较好的灵活性,能够通过参数来调节曲线形状以适应各个树种的生长情况。此外,树高的生长随着胸径的生长逐渐变大后趋于平缓,生长曲线呈S型,而这5个函数都是S型模型,因而拟合效果较好。
本研究显示:最佳模型结构(输入节点数∶隐藏层节点数∶输出层节点数)为1∶2∶1,训练数据、验证数据、测试数据的R2分别达0.712、0.717、0.717,RMSE分别达3.546、3.655、3.513。与传统模型相比,BP神经网络模型的R2均明显大于传统模型,RMSE均小于传统模型,这与黄旭光等[29]、徐志扬[30]的结果相似,说明BP神经网络在建模方面比传统模型更具有优越性。杜志等[31]通过对杉木和马尾松的树高曲线拟合得到相同结论。王轶夫等[32]在对马尾松生物量模型的研究中也发现:BP神经网络优于传统模型。由于无限逼近原理,所以在拟合过程中容易出现过拟合的情况,本研究通过输入变量与输出变量所形成的散点图判断得出:当隐层节点数为3时出现过拟合。本研究结果可为研究区马尾松人工林的经营节约调查成本,提高经营效率。充分考虑地理因素所训练出的模型具有较广的适用性[33],后续研究应充分调查不同立地条件下的该类林分,增加样本量和调查因子,增多神经网络的输入变量,以提高模型的泛化能力。
BP神经网络在拟合效果上虽然较传统模型好,但是其内部结构并不清楚,无法展示其详细的内部计算过程,这是BP神经网络的不足之处。同时,为了预防BP神经网络过早的产生过拟合,后续研究可使用改进的自适应遗传算法[34]、改进粒子群算法[35]等优化BP神经网络以达到更好的预测效果。
-
本研究选用6个林业常用的传统模型,对胸径-树高关系进行拟合,结果发现:除了Logistic模型外,其他5个候选模型均表现较好。考虑研究区较大,所以选择具3个参数的Korf模型作为马尾松胸径-树高模型。而用BP神经网络对树高进行估测显示:最佳模型结构(输入节点数∶隐藏层节点数∶输出层节点数)为1∶2∶1,BP神经网络模型的R2均明显大于传统模型,RMSE均小于传统模型,说明BP神经网络在建模方面比传统模型更具有优越性,更适合黔中地区马尾松人工林树高预测。
Diameter-height model for Pinus massoniana plantations based on BP neural network
doi: 10.11833/j.issn.2095-0756.20190486
- Received Date: 2019-08-21
- Rev Recd Date: 2020-01-16
- Available Online: 2020-07-21
- Publish Date: 2020-07-21
-
Key words:
- forest management /
- diameter at breast height /
- tree height /
- Pinus massoniana /
- BP neural network
Abstract:
| Citation: | MAO Guangxian, TAN Wei, CHAI Zongzheng, et al. Diameter-height model for Pinus massoniana plantations based on BP neural network[J]. Journal of Zhejiang A&F University, 2020, 37(4): 752-760. DOI: 10.11833/j.issn.2095-0756.20190486

|








 DownLoad:
DownLoad: