







-
精确的树种分类对于提取树木特征属性,保护物种多样性,改善区域生态环境,以及建立林木生长模型都非常重要[1-3]。目前应用较广泛的的宽谱段遥感数据由于空间和光谱分辨率均较低,难以获得精确的树种分类结果,而高光谱数据波谱范围更窄,能准确探测到具有细微光谱差异的各种地物类型,并借助纹理等特征分析,识别光谱相似树种[4]。光学数据只能探测到冠层表面信息,限制了树种识别的精度。激光雷达(LiDAR)能获取详细的树木冠层结构三维信息[5],这对于森林类型识别、森林结构特性以及冠层理化特征均具有明显优势。因此,将表征林分垂直结构信息的LiDAR数据与表征冠层水平方向信息的高光谱(AISA)数据融合,形成优势互补,理论上可以提高树种的识别精度[6]。刘丽娟等[7]利用机载LiDAR和高光谱数据融合对北方复杂森林树种进行识别时,发现融合数据树种分类精度高于仅高光谱数据的精度,总体精度达到83.88%,Kappa系数为0.80。董彦芳等[8]将高光谱遥感图像和LiDAR数据融合,利用归一化植被指数(NDVI)和主成分分析(PCA)法进行去噪和降维,再进行监督分类,实现了城市内民用房屋和树木的提取。CAO等[9]研究利用全波形激光雷达数据对亚热带森林树种分类,结果表明,6类树种的总体分类精度为68.60%,4类树种为75.80%,而针叶林和阔叶林2类为86.20%。ALONZO等[10]将高分辨率高光谱图像与LiDAR数据融合,在基于冠层尺度上对美国某些地区常见的29类树种进行分类,结果表明融合LiDAR数据后,分类精度提高了4.2个百分点。DALPONTE等[11]提出了高光谱和LiDAR数据有效结合对复杂森林地区分类的方法,并证明了支持向量机(SVM)分类器在对多源数据分类的准确性。国内外研究初步表明,将LiDAR数据与高光谱数据融合,可以有效提高树种分类的精度。目前多是针对地形平坦且树种结构单一的林型开展研究,对于地形复杂且树种多样的亚热带林区分类研究较少。在监督分类中,训练样本选取的数量和质量尤为关键,其影响往往大于分类算法的选择。王春来等[12]研究得出,基于像元分类的训练样本选取数量在24~30倍于波段数时分类精度才达到较高的水平。训练样本的选取主要采取野外实地调查法,但此法综合成本高,且采集数量有限,往往难以满足监督分类所需样本数,另外转绘到图像上时也存在人为判断的误差。若能实现训练样本的自动选取,将大大提高树种精细识别的效率和精度。因此,本研究拟在LiDAR与高光谱数据融合的基础上,试验训练样本自动化优选的方法,并通过SVM分类器基于小样本进行分类,比较不同特征变量的组合对树种分类效果的差异。
HTML
-
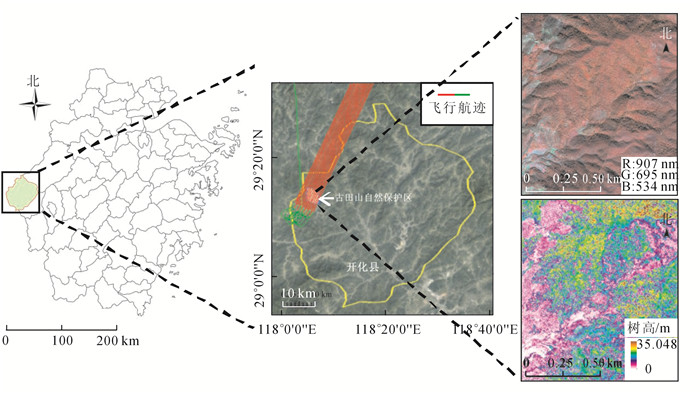
古田山国家级自然保护区(29°10′32.12″~29°17′44.33″N,118°03′56.25″~118°10′56.51″E)位于浙江省开化县城西北30 km处的苏庄境内,与江西省婺源县、德兴市毗邻,总面积为81.07 km2,属于南岭山系怀玉山脉的一部分。地处中亚热带东部,受夏季风影响较大,气候有明显的季节变化,年均降水天数为142.5 d,年均降水量为1 963.7 mm,相对湿度为92.4%。年均气温为15.3 ℃,无霜期约为250 d,冬暖夏凉,温暖湿润。由于其特殊的地理位置,分布着典型的中亚热带常绿阔叶林、常绿落叶阔叶混交林和针叶林。经济树种主要为常绿小乔木油茶Camellia oleifera,分布于海拔较低的居民区附近,高度多在2 m以上,由于在研究区内分布面积较大,因此本研究将油茶作为一个树种参与分类。考虑到研究区内阔叶林的树种种类繁多而样本受限,未细分到树种,统称为阔叶树种。本研究选择研究区的马尾松Pinus massoniana,杉木Cunninghamia lanceolata,毛竹Phyllostachys edulis,油茶以及阔叶树种等5个树种类型开展研究。图 1为研究区的地理位置及其部分图像。

Figure 1. Location of Kaihua County in Zhejiang Province (left), location and flight trajectory of National Nature Reserve of Mount Gutian (middle), hyperspectral image (upper right) and LiDARCHM image (lower right)
-
机载数据航飞于2014年10月古田山国家级自然保护区,获取了研究区高空间分辨率的高光谱和高密度LiDAR点云数据,数据获取当天晴朗少云。同步开展了部分样地的踏墈工作,同年12月又进行了样地补充调查。此次飞行的高光谱传感器为AISA Eagle Ⅱ,由超光谱探头、小型GPS/INS探头及数据采集系统组成,所得64个波段高光谱遥感图像可获得单木尺度精细的光谱信息。飞行同步搭载1台Riegl LMS-Q680i LiDAR传感器,可获得单木尺度的三维及强度信息。高光谱传感器AISA Eagle Ⅱ参数:光谱范围为400~970 nm,帧频为160帧·s-1,焦距为18.1 mm,光谱分辨率为3.3 nm,视场角为37.7°,瞬时视场角为0.037°。LiDAR传感器Riegl LMS-Q680i参数:波长为1 550 nm,激光发射角为0.5 mrad,激光脉冲长度为3 ns,视场角为±30°,最大激光脉冲重复率为400 kHz,波形采样间隔为1 ns,1 000 m高度的点密度为3.6 pts·m-2,垂直分辨率为1.15 m。
-
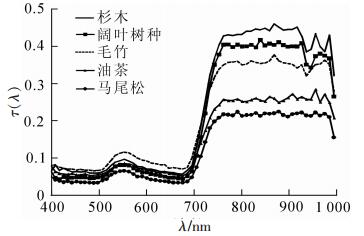
数据提供商已经对机载高光谱数据进行了系统辐射定标、几何校正和正射校正,还需对数据进行大气校正以及与LiDAR数据的几何配准。由于机载数据受大气影响相对较小,因此,本研究采用FLAASH(ENVI,美国)对高光谱数据进行大气校正。该模块用MODTRAN 4+辐射传输模型,可以校正由于漫反射引起的连带效应,还可以调整由于人为抑制而导致的波谱平滑[14]。大气校正后,消除了成像时光照和大气对地物反射率的影响,植被光谱曲线突出了谷底和峰值,并且近红外波段形成明显的高反射峰(图 2)。高光谱数据由于波段多,易造成信息冗余,因此在大气校正之后用Wilks’Lambda判别分析法选择具有代表性的特征波段。Wilks’Lambda判别分析法是基于多变量的方差分析方法,以分类样本为基础,计算组间与组内差异,综合考虑其组内和组间差异,最后得出能够反映各个波段重要性的统计量W。Wilks’Lambda计算公式具体如下[15]:

Figure 2. Spectral curves of five tree species
式(1)中:SS为样本离差矩阵, xij(i=1...r, j=1...p), SSE为组内平方和,SST为总平方和(即组间平方和与组内平方和的总和)。W值在0到1之间变化,值越接近0则说明组内的平均值差别越大,反之,值接近于1说明组内平均值越相近[16]。由Wilks’Lambda法选择的波段组合作为高光谱特征变量,记作AISA。
-
数字冠层高度模型(canopy height model,CHM)是一个重要的特征变量,通过对点云数据进行滤波分类(TerraScan,TerraSolid,芬兰),将它进行地面点和非地面点的分离,对已分类点云数据中的地面点进行TIN插值运算生成数字高程模型(digital elevation model, DEM),首回波点插值生成数字表面模型(digital surface model, DSM)。DSM与DEM进行差值运算即得到高程归一化后的CHM。另外还开展了基于形态学滤波的单木冠层分割(SEAL,激光雷达生态应用软件,中国林业科学研究院),用于分类结果的验证。
-
选择20个同名点,建立3次多项式纠正方程,对高光谱数据与LiDAR的CHM数据进行几何互配准。校正后坐标位置平均误差在2 m以内,即1个像元。
2.1. 数据获取
2.2. 数据处理
2.2.1. 机载高光谱数据的预处理
2.2.2. 机载LiDAR数据处理
2.2.3. 高光谱与LiDAR数据配准
-
“异物同谱”现象在地形复杂和树种多样的林区中普遍存在,增大了训练样本的选取难度,导致光谱相似树种的识别率偏低。LiDAR数据可以描述复杂林型垂直分布特征。本研究基于分层分类的思想,在剔除非林地后,结合LiDAR的CHM与样地统计数据,获得各树种的高度分布,针对“异物同谱”树种像元,通过比较不同树种的高度聚集情况差异,提取各树种的高度掩膜层;在各掩膜层中计算各像元与参考样本的光谱夹角。进行训练样本的自动提取;最后,计算不同的特征变量[植被指数(vegetation index,Ⅵ),PCA降维波段、高光谱AISA与LiDAR的CHM数据]利用SVM分类器对不同变量的组合进行树种分类和精度比较。技术路线见图 3。

Figure 3. Flowchart of tree species classification based on LiDAR and AISA data
-
归一化植被指数(normalized differential vegetation index,NDVI)对土壤背景的变化较为敏感。计算本研究区NDVI,通过比较林地与非林地的NDVI值,并结合LiDAR的CHM数据,设置NDVI大于0.3,高度大于2 m的像元为林地,去除非林地光谱信息的干扰。
-
采用Wilks’Lambda波段选择法对64个波段的高光谱进行降维,选出数据冗余小、噪声少且能够表达植被光谱特征的14个波段[17]作为特征变量AISA,这14个优选波段为波段7,波段13,波段16,波段18,波段21,波段22,波段24,波段31,波段33,波段35,波段37,波段42,波段55和波段58,它们的中心波长分别为452.11,506.76,534.44,553.02,581.07,590.46,609.29,675.78,694.91,714.09,733.32,781.54,907.45和936.49 nm。
-
以往研究多基于NDVI,EVI(enhanced vegetation index)等宽波段指数,而反映色素含量的指数使用较少。因此,本研究利用随机森林法对16个高光谱植被指数变量按重要性排序[18]。平均精度较少量(mean decrease accuracy, DMA)和平均基尼指数减少量(mean decrease gini,DMG)是重要性评价的指标,一般两者的值越大表示该变量的重要性越大。结合研究内容,本研究依据平均精度减少量选取排名前8的植被指数作为待选特征变量(表 1)。
变量 DMA DMG 结构不敏感色素指数SIPI 16.781 221 7 1.059 741 828 改进红边比值植被指数MRESRI 14.090 665 4 0.921 555 203 改进红边归一化植被指数MRENDVI 13.784 894 3 0.890 267 344 红绿比值指数RGRI 10.034 705 4 0.887 654 227 花青素反射指数2ARI2 8.631 932 8 0.931 436 794 Vogelmann红边指数VREI 4.864 365 4 0.638 686 021 归一化植被指数NDVI 4.070 067 8 0.755 367 097 花青素反射指数1ARI1 3.909 291 8 0.358 767 829 Table 1. Importance sorting of vegetation index (No.1~8)
-
主成分分析(PCA)也是一种常用的波段降维手段。PCA变换后的前4个主成分包含了所有波段中95%以上的信息量。前4个PCA的标准差分别是8 121.92,2 056.43,448.07和336.14,PCA1和PCA2的值远大于PCA3和PCA4。因此,PCA1和PCA2作为待选特征变量参与分类研究。
-
数字冠层高度模型作为LiDAR的特征变量,将该变量记作CHM。
-
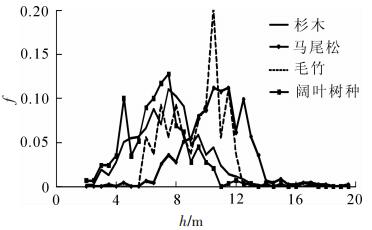
树种的结构和高度分布因树木生长习性不同而有差异。由于“异物同谱”现象使得光谱特征近似的不同树种的训练样本难以选择。为解决这一问题,本研究基于样地统计数据,根据各树种的高度分布,对数字冠层高度模型进行分层掩膜,提取出各树种高度集中分布层的高光谱像元作为训练样本。本研究各树种高度分布频率如图 4,0.5 m的区间归为一级。其中阔叶树种与杉木的高度分布曲线相近,毛竹和马尾松在高度层上与其他树种差距较大。根据各树高分布频率,最终选取掩膜高度为:阔叶树种4.0~4.5 m和6.0~7.0 m;杉木7.5~8.5 m;毛竹10.0~10.5 m;马尾松12.0~14.0 m。由于外业未采集油茶样地信息,因此没有列出,通常油茶高度为2~3 m。

Figure 4. Distribution frequency chart of height for tree species
-
光谱角填图法(spectral angle mapping,SAM)可以计算出2个光谱之间的夹角,夹角越小,光谱越相近,两者属于同一类的可能性越大。
式(2)中:α为空间向量A和B的夹角,取值$ 0 \sim \frac{{\rm{ \mathsf{ π} }}}{2}$,N表示数据的波段数,其中:Ai,Bi表示第i个波段上的数值并分别代表测试光谱和参考光谱。计算每个高度层内各像元与参考光谱之间的光谱夹角,并调整夹角阈值,阈值越小,两光谱向量匹配越好,是同类的可能性越大。如设置阈值为0.03,代表两像元光谱夹角α小于0.03弧度时,认为该像元与参考像元为同一类,实现训练样本的自动识别。
-
研究区地形起伏较大,大部分区域数据难以获取,导致验证样本数量有限。本研究结合样地实测数据和高空间分辨率图像,增补阔叶树种、马尾松、毛竹、杉木、油茶的验证样本(表 2),使其均匀分布在研究区内。后续各变量组合的分类精度验证使用同一套验证样本。
项目 样本点数/个 阔叶树种 马尾松 毛竹 杉木 油茶 总计 增补前 17 16 13 19 18 83 增补量 14 15 7 15 13 64 Table 2. Number of sample points of five tree species

3.1. 去除非林地
3.2. 特征变量选择
3.2.1. 高光谱
3.2.2. 植被指数
3.2.3. 主成分分析
3.2.4. 激光雷达
3.3. 训练样本自动提取
3.3.1. 基于树高分层
3.3.2. 计算光谱角
3.4. 增补验证样本
-
以错分毛竹样本为例。研究区毛竹林为人工林,与阔叶树种混生,当人机交互直接在影像上选择训练样本时,边缘像元往往是混合像元,获得的是2个类型的均值光谱,造成部分毛竹与阔叶树种混分。图 5是错分毛竹样本在高光谱图像上的地理位置,像元植被类型应为毛竹,但由于人机交互训练样本选择误差,错分为阔叶树种,下文称此类像元为错分毛竹样本。

Figure 5. Location of mis-classification on the hyper spectral image
图 6为分层前后选取的阔叶树种、毛竹训练样本以及错分毛竹样本的光谱特征图。可以看出未分层前选取的阔叶树种与毛竹训练样本光谱特征曲线比较接近,而分层后两者光谱曲线之间差异较大。

Figure 6. Comparison of spectral characteristics between broad leaved forest and moso bamboo
计算错分毛竹样本与分层前后阔叶树种、毛竹样本之间的光谱角(表 3),分层后训练样本间区分度更大,更精确。本研究利用数字冠层高度模型分层掩膜并计算光谱夹角自动提取训练样本的方法,降低了阔叶树种与毛竹的混分概率。
项目 分层前夹角 分层后夹角 阔叶树种样本 毛竹样本 阔叶树种样本 毛竹样本 错分毛竹样本 0.029 0.038 0.060 0.014 分类结果 阔叶树种 毛竹 Table 3. Spectral angle between broad leaved forest and moso bamboo before and after stratification
-
经自动化分层选取的训练样本,充分利用CHM的高度信息,减少因光谱相似而高度不同的树种光谱信息的相互干扰,同时使训练样本的选择高效且高精度。本研究使用混淆矩阵对各特征变量组合的SVM分类结果进行精度评价。
-
结果表明:AISA+SIPI分类总体精度可达77.55%,高于仅AISA的总体精度65.31%。其余Ⅵ变量与AISA融合后的分类精度均低于SIPI。分析原因发现,当叶片相对含水量较低时,SIPI与类胡萝卜素/叶绿素的比值具有较好的线性关系。水分缺失导致叶绿素因降解而减少,类胡萝卜素/叶绿素的比值升高,SIPI也随之升高[19]。本研究的数据获取于10月,此时植物体内水分开始流失。因此,在本研究中SIPI能做为树种识别的指示性变量,且另一方面证明重要性排序的可靠性。
-
对AISA+PCA变量进行精度分析时,加入第1主成分PCA1的总体精度是70.07%,比加入PCA2高5.44%。所以PCA1比PCA2更适合树种识别。
-
特征变量AISA,CHM,SIPI和PCA1组合的分类结果总体精度和Kappa系数如表 4所示。每小组中融合了CHM变量比未融合CHM变量的分类精度高;AISA+SIPI比仅AISA的总体精度有明显提高,而AISA+CHM+SIPI的总体分类精度和Kappa系数达到最高,故SIPI有利于树种分类。然而添加PCA1这个变量后,最终分类效果均不优。这说明本研究选用Wilks’ Lambda法选择的波段,在树种识别应用中降维效果优于PCA法。因此,本研究的最佳分类变量的组合为AISA+CHM+SIPI。由于阔叶林内树种种类复杂,常绿和落叶的树种间光谱相互干扰,加之空间上纯林区较少,阔叶树种仍存在混分现象(表 5),与油茶、毛竹、针叶林混杂生长,影响了阔叶树种的分类精度。由于杉木和阔叶树种样本的高度分布频率比较近似,两者的训练样本提取困难,混分的可能性比较高;油茶为常绿小乔木,其冠形和叶片与很多常绿阔叶树种相似,特别是高度相近的像元,仍会存在一小部分与阔叶树种混分;毛竹与阔叶树种的光谱比较近似,虽然经过分层分类的毛竹与阔叶树种混分较少,但由于少许像元距离相近,仍然有混合像元存在,产生少量混分。马尾松的光谱近红外平台峰值低于其他4类,较易区分。
特征变量 总体精度/% Kappa系数 AISA 65.31 0.56 AISA+CHM 76.87 0.71 AISA+SIPI 77.55 0.72 AISA+CHM+SIPI 89.12 0.86 AISA+PCA1 70.07 0.62 AISA+CHM+PCA1 74.15 0.68 AISA+SIPI+PCA1 74.15 0.68 AISA+CHM+SIPI+PCA1 78.23 0.72 Table 4. Overall accuracy and Kappa coefficient of the classification results
分类样本 参考样本 阔叶树种 马尾松 毛竹 杉木 油茶 总计 阔叶树种 27 4 0 2 3 36 马尾松 0 27 0 0 0 27 毛竹 1 0 19 2 0 22 杉木 3 0 0 30 0 33 油茶 0 0 1 0 28 29 非林地 0 0 0 0 0 0 制图精度/% 87.10 87.10 95.00 88.24 90.32 — 用户精度/% 75.00 100.00 86.36 90.91 96.55 — Table 5. Accuracy and confusion matrix of five tree species classification under the combination of the AISA+CHM+SIPI
-
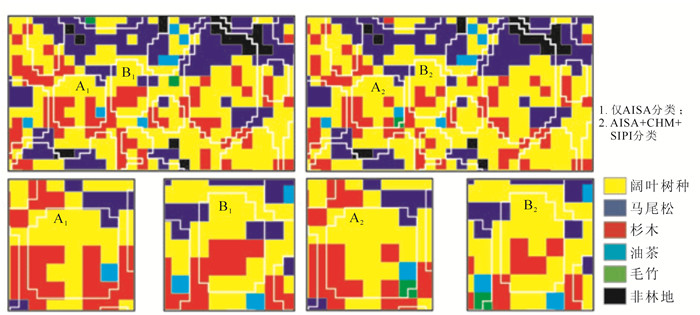
分析本文高光谱的空间分辨率为2 m,一般单木树冠范围内的像元应为同一类,然而由于树冠间相互遮挡,单木树冠内不可避免出现多个树种的情况。叠加经单木冠层分割而得的树冠矢量图比较仅AISA和AISA+CHM+SIPI分类结果(图 7),进一步得出AISA+CHM+SIPI结果中树冠内均质性更高。通过计算树冠内树种所占比例(正确分类像元数/树冠内总像元数)可说明分类效果,比例越大,分类效果越好(表 6)。AISA+CHM+SIPI的分类结果在单木尺度上也优于仅AISA的结果,树种纯度可达70.00%以上。

Figure 7. Comparison of classification results based on individual canopy
参考类别 序号 组别 总像元数 分类类别 比例/% 阔叶树种 马尾松 毛竹 杉木 油茶 非林地 合计 阔叶树种 1 A1 25 14 1 0 9 1 0 11 56.00 A2 19 1 0 5 0 0 6 76.00 2 B1 15 6 1 1 6 1 0 9 40.00 B2 11 0 0 4 0 0 4 73.00 Table 6. Comparsion of the percentage in the canopy
-
基于SVM的高光谱AISA+LiDAR变量CHM+植被指数SIPI的分类结果制专题图(图 8)。

Figure 8. Thematic map of the classification for AISA+CHM+SIPI data with SVM
4.1. 训练样本分层自动提取


4.2. 分类精度比较
4.2.1. AISA+Ⅵ变量
4.2.2. AISA+PCA变量
4.2.3. 4类特征变量组合
4.2.4. 单木尺度的精度
4.3. 分类结果专题图

-
高光谱是光学被动遥感数据,其窄波段特性在较小的空间尺度上能区分地表细微变化,在树种识别方面有显著优势。但由于“同物异谱、异物同谱”现象的存在,导致分类精度受限。机载LiDAR是主动遥感数据,可获得树种垂直结构及强度信息,与高光谱优势互补,有效解决不同高度下不同地物因具有相似光谱特征而导致的混分问题。采用分层训练样本自动提取技术,不仅提高了训练样本选取的速度还有效提高训练样本选取精度,更从一定程度上尽可能地避免混分现象。
本研究结合高光谱与机载LiDAR的数据优势,为评估LiDAR垂直结构信息与特征变量参与分类的贡献,比较了基于AISA,CHM,SIPI和PCA1这4种不同变量组合的分类精度。其中AISA+CHM+SIPI变量组合的分类精度最高,其总体精度和Kappa系数分别为89.12%和0.86,比仅AISA分类的总体精度高23.81%,比AISA+CHM高12.25%,比AISA+SIPI高11.57%。但结果同时表明,PCA降维变量的分类贡献要明显弱于SIPI。本研究区为典型的亚热带森林,其中阔叶林内树种种类繁多,与其他类型的树种混杂生长,所以纯林区较少,易产生混合像元。在AISA+CHM+SIPI的分类结果中阔叶树种的制图精度和用户精度最高,分别为87.10%和75.00%,优于AISA+CHM(70.97%,66.67%)以及仅AISA的分类结果(41.94%,61.90%)。这说明将机载LiDAR数据CHM与高光谱AISA融合,并添加植被指数SIPI能有效区分混合像元并提高分类精度,对古田山国家级自然保护区进行树种类型的精细分类具有可行性。但由于阴影区域的存在、树冠间相互遮挡、少部分边缘像元的光谱混合等,对树种分类的精度有一定影响。后续拟研究基于高空间分辨率数据的像元解混技术,期望能有效提高复杂林区的树种识别精度。
 DownLoad:
DownLoad: