








-
水果产业是中国种植业中仅次于粮食、蔬菜的第三大产业,在国民经济中占有重要地位。中国是世界上最大的水果生产国[1],如苹果Malus pumila,梨Pyrus spp.,甜樱桃Prunus avium等,但国产水果的质量不容乐观,培育和检测高质果树是当前迫切需要解决的现实问题。遥感技术(RS)和地理信息系统(GIS)的集成可以提供强大的空间决策支持系统,为检测果树的生长状况、健康状况和果树分类等[2-4]提供了技术基础;随着遥感技术的发展,植物物种信息提取已有大量研究[5-6],也为果树的遥感信息带来了可能。近红外光谱技术由于其高分辨率特性被广泛应用,如邢东兴等[7]利用冠层和叶片的实测高光谱数据对果树的病虫害、冻害、营养元素与微量元素含量等进行了研究;朱西存等[8-9]基于高光谱数据,建立了苹果花磷素和氮素含量的预测模型,效果较好;雷彤等[10]基于多光谱和数码照相技术发现蓝光、红光和近红外波段为苹果花期的敏感波段,花期光谱特征变化与花叶比和花树比呈现较好的相关性;李子艺等[11]采用BP神经网络对南疆盆地主栽果树进行基于冠层光谱的分类,而且分类精度较高。国内外基于光谱技术对果树的研究基本局限于病虫害预警、施药、叶面积指数估计和冠层生物量检测、产量预测和果品品质评估等方面[12-13],对于果树花期分类的研究涉及极少。本研究采集并分析了常见4种果树花期的光谱数据,并选取了相关特征波长以及归一化植被指数(INDV)和比值植被指数(IRV)分类建模,以期探寻利用地面全波段光谱测试数据对果树树种进行科学识别的有效方法与途径,并为今后高空遥感技术进行果树树种识别提供理论基础。
HTML
-
研究区位于辽宁省兴城市(40°16′~40°50′N,120°06′~120°50′E),地处东北平原腹地,面积约2 147 km2,属于北温带大陆性气候。年平均降水量为600 mm,冬季平均气温为-13.0 ℃,夏季平均气温为25.0 ℃。兴城市的水果栽培以梨,苹果,桃Amygdalus persica,杏Armeniaca vulgaris为特色,是中国农业部认定的优质水果生产基地。
2016年4月28日-2016年5月10日,选取树高和胸径基本一致的梨‘早酥’‘Zaosu’,苹果‘华红’‘Huahong’,桃‘铁桃’‘Tietao’,杏‘银白杏’‘Yinbaixing’等4个果树品种,10株·品种-1,3~4个测定点·株-1测量样本花。测定点选取的标准为花束比较紧凑且都在盛花期。
采用ASD公司的FieldSpec 3便携式光谱辐射计,测量盛花期待测树种花的光谱反射率(R)。光谱范围为350 ~2 500 nm;光谱采样间隔为1 nm;波长精度为±1 nm。
-
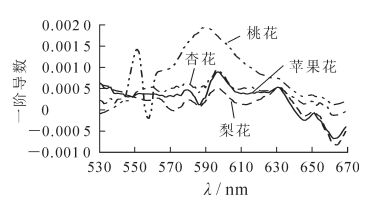
光谱探头垂直于被测点,距离约20 cm,测定光谱数10条·次-1,3重复·处理-1。为保证数据的有效性与准确性,隔10 min进行1次标准白板矫正。获得待测树种盛花期花的光谱数据如图 1所示。

Figure 1. Characteristics of remote sensing reflectance spectra of fruit trees at different flowering stages
-
环境和机器本身的影响会使得到的光谱数据夹杂高频噪声,同时各种随机因素也有可能造成光谱的基线漂移或旋转,因此需对得到的数据作异样光谱曲线剔除和光谱曲线5点平滑处理等预处理。得到花期冠层光谱数据分别为梨110条,苹果170条,桃100条,杏60条。偏最小二乘判别分析(PLS-DA)和正交偏最小二乘判别分析(O-PLS-DA)采用Kennard-stone[14]方法对样品集进行划分,分别得到330个建模集、55个验证集和55个预测集。BP神经网络样本划分比例为75%,15%和15%。
-
用Excel 2010,ViewSpec Pro(Version 5.6.8, ASD Inc.,美国),MatlabR2014a软件(Version 8.3.0.532,The MathWorks,美国)和复杂多变量数据智慧处理软件系统(ChemDataSolution 1.1.0,大连达硕信息技术有限公司,中国)对数据进行分析并建模。
-
⑴偏最小二乘判别分析(PLS-DA)[15]算法是基于偏最小二乘回归的判别分析方法,基本思想是根据已知样品集的特征,建立定性分析模型。首先建立校正样本集的分类变量y;然后将y与光谱数据进行PLS分析,建立分类变量y与光谱数据x间的PLS回归模型;最后根据模型计算检验集(未知样本)的分类变量值yP。具体判别方法是:①当yP>0.5,且偏差<0.5时,判定样本属于该类;②当yP<0.5,偏差<0.5时,判定样本不属于该类;③当偏差≥0.5时,判别不稳定。⑵正交偏最小二乘判别分析(O-PLS-DA)[16]相似于PLS-DA,与PLS-DA基于偏最小二乘回归分析不同的是,前者是基于正交偏最小二乘法辨别分析,是在PLS的基础上提出的一种新的数据分析方法。该方法将x变量分为“y-predictive”和“y-orthogonal”2个部分,其中“y-predictive”中的第一潜变量涵括x与y间的最大变化与相关性,而“y-orthogonal”则描述x与y中不相关的信息。因此,该方法的特点是可以剔除自变量x中与分类变量y无关的变化,使模型变得易于解释,其判别效果及主成分得分图的可视化效果更加明显,使模型的解释与诊断能力更加优化。⑶基于误差反向传播算法的多层前向神经网络(Back Propagation)即BP神经网络算法[17-18]是一种不同于传统方法的人工智能方法,其主要思想是将学习过程分为2个阶段:一是正向传播,二是误差反向传播。利用输出后的误差来估计前一层的误差,再用这个误差估计更前一层的误差,如此一层一层反传,使获得所有层的误差估计。这样就形成了输入层的误差沿着相反的方向逐级传递的过程,因此,该算法也称为误差反向后传算法,简称BP算法。
1.1. 研究区概况及样品仪器
1.2. 研究方法
1.2.1. 光谱扫描
1.2.2. 光谱处理
1.2.3. 数据处理
1.2.4. 建模方法
-
近红外光谱通常包含数以千计的波长变量,且远大于样本量,利用全波段数据进行建模时,并非每个波长都能提供有用信息,大量的冗余数据会增加建模工作量。本研究采用连续投影算法(SPA)[19],寻找含有最少冗余信息的变量组合,使变量间的共线性最小。迭代结果如图 2所示,按筛选出的顺序排序特征波长分别为541,395,370,682,1 839,2 481,1 268 nm。

Figure 2. Feature extraction results of SPA
对4类树种花的光谱数据求平均值(图 3),发现在430 ~ 1 000 nm波段下光谱反射率由高到低的顺序为:苹果>梨>杏>桃;在1 100~1 400 nm波段下,光谱反射率由高到低的顺序为:苹果>梨>桃>杏;在1 500 ~ 1 800 nm光谱反射率由高到低的顺序为:苹果>梨>桃>杏。对光谱数据求导数可以反映光谱反射率的上升速度,从图 4可知:桃在562 ~ 675 nm波段时反射率上升最快,其次是杏,苹果,梨;在695 ~ 750 nm波段时,反射率上升速度有所变化,速度由高到低为苹果>梨>桃>杏。由此可知:在562 ~ 675 nm和695 ~ 750 nm波段下果树花期光谱波形有差异,不能被全部采用,因此连续投影算法(SPA)将此2个波段大部数据排除,只选择了此波段的峰值590 nm,720 nm作为建模数据;植被指数是能反映植物生长状况的指数,常用的植被指数有IRV和INDV,为了提高模型的精度本研究又增加这2个植被指数用于建模。综上分析,最终选取的特征波长为370,395,541,590,682,720,1 839,2 481,1 268 nm以及IRV和INDV。

Figure 3. Mean spectral reflectance of 4 fruit tree species

Figure 4. First derivative spectral reflectance of 4 fruit tree species
-
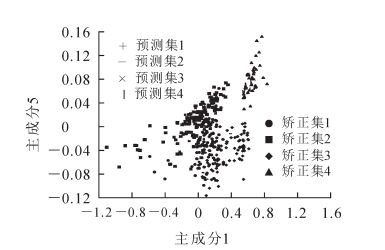
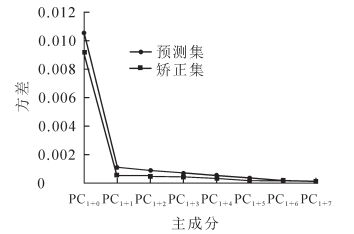
从图 5和表 1可知:残差方差和误差随着模型输入主成分数量的增加先减小而后稳定,决定系数R2值则先增加而后稳定。当主成分数值显示为6时,得到均方误差最小值为0.05,决定系数最大值为0.79(表 1);因此,在随即建立的PLS-DA模型中选择了6个主成分,由此得到的得分图如图 6所示,显示效果较好。

Figure 5. Residual variance of PLS-DA
主成分参数 模型决定
系数R2预测集决
定系数Q2误差 测试集误差 PC1 0.22 0.22 0.20 0.20 PC2 0.44 0.44 0.08 0.08 PC3 0.53 0.52 0.08 0.09 PC4 0.59 0.58 0.04 0.05 PC5 0.66 0.65 0.08 0.08 PC6 0.79 0.78 0.05 0.05 PC7 0.78 0.77 0.06 0.06 PC8 0.79 0.78 0.05 0.06 Table 1. Changes of errors and R2 for every principal parameters

Figure 6. Scores of PLS-DA
通过使用所选择的最佳波长和植被指数建立的PLS-DA模型如下:y=-3.30R369+6.20R394-7.99R540+5.51R681-1.79R590-4.25R720+3.29R1267-0.98R1838+3.44R2480-12.50INDV+0.45IRV+8.22。表 2显示了不同果树树种在PLS-DA模型下的预测精度。结果表明:对于苹果、桃和杏的预测精度较高,梨的准确度略低。不同果树物种的检测精度差异很大。预测集样本总体识别率为76.36%。
种类 识别次数/次 识别率/% 梨 苹果 桃 杏 梨 3 12 0 0 20.00 苹果 0 20 0 0 100 桃 0 0 9 1 90.00 杏 0 0 0 10 100 识别率/% 100 62.50 100 90.91 76.36 Table 2. Classification results of PLS-DA model for four fruit tree species
-
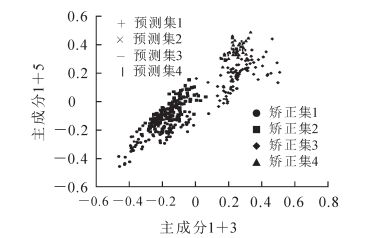
从图 7和表 3可知:残差方差和误差随着模型输入主成分数量的增加先减小而后趋于稳定,相关系数R2则先增加而后趋于稳定增加。当主成分数值显示为7时,得到均方误差最小值为0.04,决定系数R2最大值为0.85(表 3);因此,在建立O-PLS-DA模型中选择了7个主成分作为指标,得到得分图如图 8所示。此模型下分类效果比PLS-DA更明显。

Figure 7. Residual variance of O-PLS-DA
主成分参数 模型决定
系数R2预测集决
定系数Q2误差 测试集误差 PC1 0.05 0.04 0.34 0.34 PC2 0.30 0.29 0.18 0.18 PC3 0.53 0.51 0.07 0.08 PC4 0.67 0.64 0.06 0.06 PC5 0.79 0.76 0.05 0.05 PC6 0.82 0.81 0.04 0.04 PC7 0.84 0.82 0.04 0.05 PC8 0.85 0.84 0.04 0.04 Table 3. Changes of errors and R2 for every principal parameters

Figure 8. Scores of O-PLS-DA
建立的O-PLS-DA模型如下:y=0.01R369-0.06R394-1.08R540-0.52R681-0.89R590-0.99R720-0.96R1267-0.51R1838+0.10R2480-0.28INDV-2.58IRV+2.16。表 4显示了不同果树树种的O-PLS-DA模型的预测精度。结果表明,对于苹果、桃和杏的预测精度较高,梨的准确度略低,但比PLS-DA略有提高。不同果树品种的检测精度差异很大。预测集样本总体识别率为81.82%,比PLS-DA模型精度有所提高。
种类 识别次数/次 识别率/% 梨 苹果 桃 杏 梨 6 8 1 0 40.00 苹果 0 20 0 0 100 桃 0 1 9 0 90.00 杏 0 0 0 10 100 识别率/% 100 68.97 81.82 100 81.82 Table 4. Classification results of O-PLS-DA model for detecting fruit tree species
-
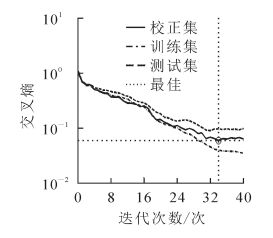
图 9表明:在训练34次后交叉熵趋向于平稳,即BP神经网络算法在迭代34次时得到最稳定模型,误差最优为0.04~0.05(图 10),在预测集中有部分杏被误认为桃,总体识别率达到93.90%(表 5),与前面2种识别方法相比,BP神经网络算法具有自动划分样本集的功能,方法有效,识别率高。由于BP神经网络是有输入层、隐含层、输出层的非线性模型,因此没有具体的模型表达式。

Figure 9. Number of iterations for BP model

Figure 10. Errors for BP model
种类 识别次数/次 识别率/% 梨 苹果 桃 杏 梨 8 0 0 0 100 苹果 0 20 0 0 100 桃 0 0 23 1 95.80 杏 0 0 3 11 78.60 识别率/% 100 100 88.50 91.70 93.90 Table 5. Classification results of BP model for detecting fruit tree species
2.1. 光谱分析及特征提取


2.2. PLS-DA模型对未知样品的预测效果

2.3. O-PLS-DA模型对未知样品的预测效果
2.4. BP模型对未知样品的预测效果
-
基于对研究区ASD Fieldspec 3测量数据和现场调查分析,探讨了利用近红外光谱技术自动检测果树盛花期花的光谱反射率,并以此建立函数模型实现对果树树种的映射;验证了近红外光谱技术作为检测花期果树品种的可行性,为快速监测果树生产状况提供了理论基础,为果树科学经营和数字化管理提供科学依据。
-
对4种果树花期的光谱数据进行预处理和SPA波段选择,选取541,395,370,682,1 839,2 481,1 268,590,720 nm等9个特征波长并获得该波长下花的光谱反射率,同时加入植被指数IRV和INDV共11个指标值作为分类模型的自变量;研究发现波段优先选择的是可见光波段(390~780 nm),其次是近红外波段(780~3 300 nm),此组合波段对待测果树的分类效果较好。
-
对所选波段进行了3种方式的建模。尽管O-PLS-DA在PLS-DA基础上作了改进,但此两者将梨误判为苹果的概率较大,分析原因可能是梨花和苹果花在盛花期光谱数据较为相似,今后若用线性模型对果树分类,应考虑增加花蕾期数据或结合其他信息进行识别。BP神经网络与前2种方法相比有更高的识别正确率,原因在于BP神经网络具有很强的学习能力,可以实现输入与输出之间的高度非线性映射,得到较为理想的分类效果,因此被广泛的应用在各品种识别领域中[11, 20-22]。本研究通过BP神经网络算法对4种果树花期树种进行分类,最高精度达到93.90%,说明采用BP神经网络算法能够对盛花期果树树种进行基于冠层光谱的分类,且达到较高的识别精度。
-
本研究只建立了4个果树品种的识别模型,在今后研究中可以加入更多果树品种的检测模型。植被指数方面选择了INDV和IRV,今后可以考虑加入更多光谱指数,如绿度植被指数(IGV)和垂直植被指数(IPV)等;这些参数在不同树种中相关性也各不相同。本研究检测了果树花期花的光谱差异,但没有考虑不同花卉的生理和生化参数,在今后应考虑碳、氮、磷等元素或微量元素对其光谱反射率的影响。BP神经网络是一种高效、稳定的模型,但是它对输入数据的质量和数量都有一定的要求,尤其在波段输入数量上会出现过拟合的现象,在研究中应该引起重视。
 DownLoad:
DownLoad: