






-
植物病害严重威胁作物的产量和品质,如何高效监测作物健康状况是保障农业生产的关键[1−3]。传统病害识别依赖农民经验或农业专家现场判断,但受限于经验不足、专家稀缺和成本高等问题,难以及时准确地应对新发病害。因此,研发高效智能的植物病害识别算法具有重要意义。
近年来,深度学习技术在农业图像分析领域取得了显著进展,深度学习算法逐步取代机器学习算法,成为植物病害分类的主流方法[4−6]。尽管采用AlexNet[7]、VGGNet[8]等卷积神经网络在植物病害识别中取得了良好效果,但深度卷积神经网络在处理跨域、异质病斑图像以及应对新类别病害时表现出明显的适应性不足。因此,如何在样本稀缺的条件下实现对植物病害的准确识别,已成为当前研究关注的重点。
小样本学习(FSL)能够在样本有限的条件下,快速适应新类别识别需求。近年来,小样本学习已成为农业视觉领域解决数据稀缺问题的重要研究方向。基于度量的方法因其直观的理论基础和优异的性能,成为小样本学习领域的主流研究方向[9]。研究人员探索了多种度量学习方法,如基于类均值表示的欧氏距离[10]、脊回归方法[11]以及图神经网络[12]等。在农业领域,也有部分小样本分类的研究。这些方法通过生成对抗网络[13]、度量学习损失[14]、聚合损失函数[15]等策略,在特定场景下取得了一定成效。然而,这些方法仍存在特征表达不足、跨域泛化能力弱等问题,尤其在应对复杂背景与异质数据时性能下降明显。基于转换器(Transformer)架构的视觉模型,因其强大的全局特征建模能力,逐渐成为农业图像识别领域的新趋势。现有方法主要通过融合迁移学习与小样本学习降低数据依赖[16],利用轻量级注意力机制结合高效Transformer架构[17],进行局部与全局特征协同建模[18],以及引入掩码自编码器MAE[19]等方式,增强模型的小样本适应能力,从而提升植物病害识别的性能与鲁棒性。尽管上述研究在植物病害小样本识别方面取得了一定进展,但对数据预处理依赖性强、计算资源需求高以及特征表达能力受限等问题仍然存在。鉴于此,本研究基于视觉转换器(Vision Transformer),将小样本转换器[20]和知识蒸馏思想引入到植物病害识别当中,设计出一种全新的增强型上下文感知知识蒸馏框架(ECKD),通过改进监督式掩码知识蒸馏思想,融合全局特征信息与局部特征信息,解决模型识别效率低和应用可行性的问题,以期为植物病害小样本智能识别提供理论依据和方法支持。
-
小样本学习任务中数据集通常划分为源数据集(Ds)和目标数据集(Dt)。Ds用于模型训练,提供大量标注样本以学习通用特征表达;Dt用于模型评估,包含仅有少量样本的新类别。在给定的N-way K-shot (5-way 5-shot和5-way 1-shot)任务中,每个任务包含支持集样本(Dsup)和查询集样本(Dqy),任务表示为Dtask=(Dsup, Dqy)。其中,Dsup和Dqy分别从Dt的N个类别中采样。Dsup包含每个类别的K个样本,用于估计类别原型,Dqy则用于评估模型的分类性能。在小样本学习任务中,目标是将Dqy中的样本正确分类到这N个类别中。因此,本研究的重点是在Ds上训练1个具有良好泛化能力的特征提取器,在Dt上使用特征提取器进行小样本分类任务,使其能够在Dt的小样本任务中实现出色的分类性能。
-
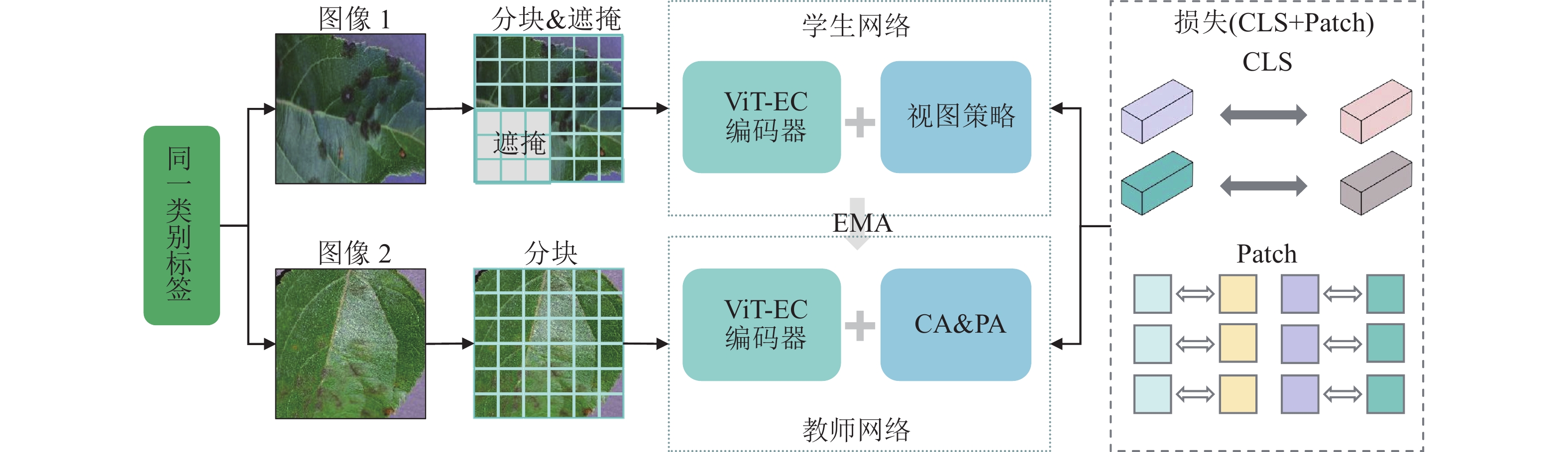
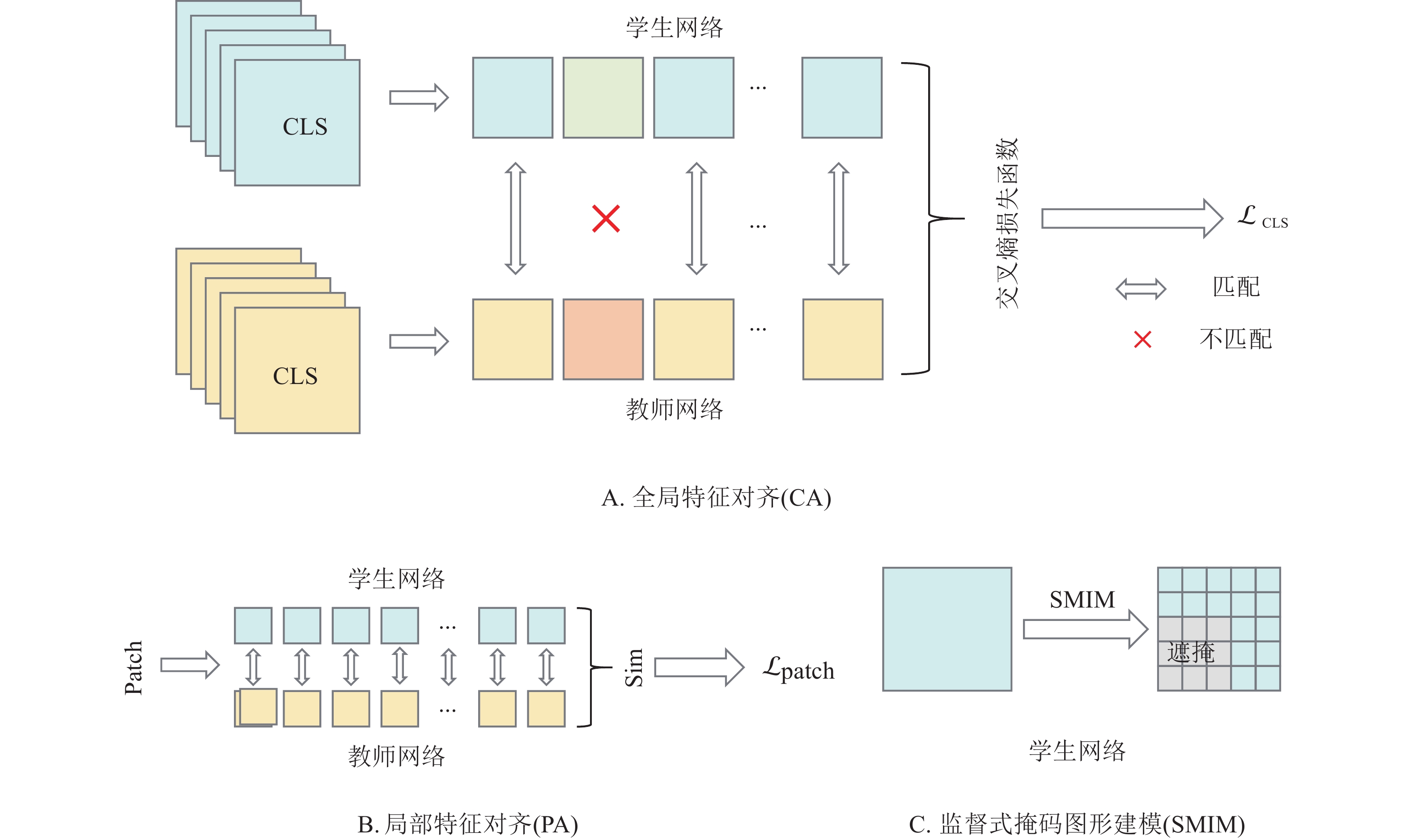
本研究提出的ECKD旨在提升模型在植物病害识别任务中的表现,图1为ECKD的框架结构。该框架包含学生网络和教师网络2个部分,网络之间通过指数移动平均(EMA)保持协同。如图2所示:ECKD融合了全局特征对齐(CA)、局部特征对齐(PA)和监督式掩码图像建模(SMIM) 3种视图策略,这些策略用于提升学生网络在小样本学习中的泛化能力和特征表达能力。ECKD实现过程如下:首先,从同一种类别标签中输入2张不同的图像,图像1在进行分块处理后采用遮蔽增强策略输入学生网络,图像2则在分块处理后保持完整输入教师网络。随后,学生网络和教师网络中的图像块均通过ViT-EC编码器转化为全局特征(CLS)和局部特征(Patch),学生网络与教师网络通过EMA实现参数更新。最后,通过图像1和图像2的全局特征和局部特征计算CLS和Patch的损失,实现全局特征和局部特征对齐。ECKD通过ViT-EC编码器和视图策略实现增强知识蒸馏,保证学生网络能够在不完整输入数据的情况下,从教师网络中学习到更丰富的全局和局部特征表示,最终提升模型在小样本学习场景下的特征表达能力和泛化能力。
Figure 1. Enhanced context-aware knowledge distillation (ECKD) structure flow
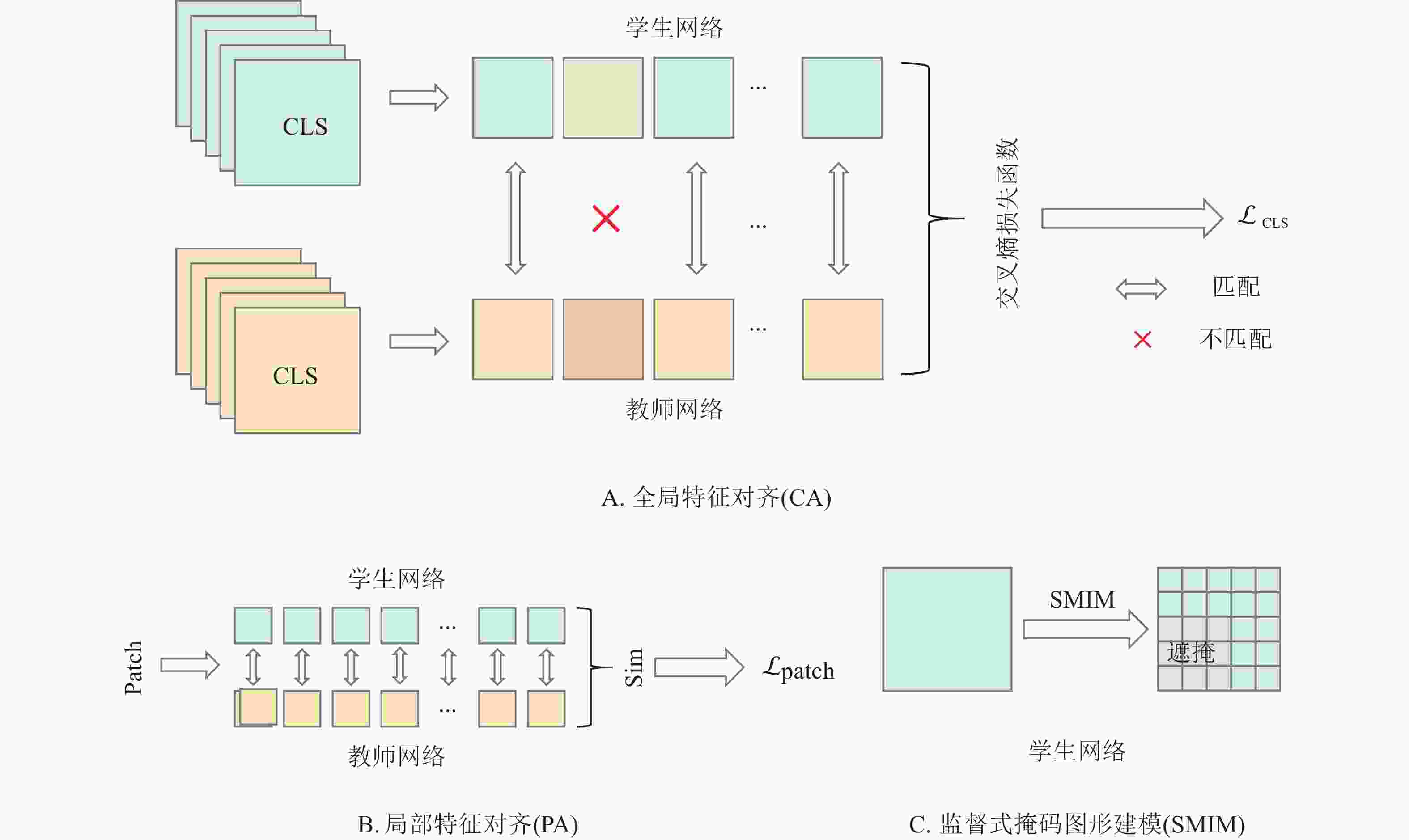
Figure 2. Three view strategies of enhanced context-aware knowledge distillation (ECKD)
-
模型对全局特征的捕捉能力决定其在稀缺训练数据下的泛化能力和性能表现。全局特征对齐策略的核心思想是:虽然同一类别不同样本的局部特征存在差异,但其全局特征表征应保持高度的一致性,这种一致性可以通过跨视图知识蒸馏来实现。首先,从同一类别的图像集合中采样2张不同的图像($ {x}_{\mathrm{a}},{x}_{\mathrm{b}} $),并生成对应的增强视图$ {{V}}_{\text{a}} $和$ {{V}}_{\text{b}} $。随后,通过模拟图像局部遮挡的场景对视图$ {{V}}_{\text{a}} $施加块状掩码从而生成损坏的视图$ {\hat{V}}_{\mathrm{a}} $,并将掩码区域替换为可学习向量集合。最后,教师网络接收未掩码的视图$ {{V}}_{\text{b}} $,通过ViT-EC编码器生成CLS的投影分布($ {P}_{\text{CLS}}^{\mathrm{t}} $)。学生网络处理掩码视图$ {\hat{{V}}}_{\text{a}} $,通过ViT-EC编码器输出投影分布($ {P}_{\text{CLS}}^{\mathrm{s}} $)。公式(1)为基于交叉熵的监督对比损失($ {\mathcal{L}}_{\text{CLS}} $),$ C $表示同一类别的内部交叉视图对。通过全局特征对齐,学生网络会在CLS上学习到更准确的全局类别信息,明显提升模型在小样本学习任务中的分类性能。
-
在全局特征对齐的基础上进一步引入局部特征对齐策略,有利于充分挖掘图像的细节信息。局部特征对齐任务假设:同一类别的不同图像在局部细节上可能有所不同,但仍有一些相似的语义信息,通过在这些共享区域进行蒸馏,模型能学习更具泛化能力的特征。教师网络从未损坏视图$ {V_{\mathrm{b}}} $中提取第j个分块(Patch)的嵌入特征($ {{F}}_{{j}}^{\text{t}} $)。然后,在学生网络的损坏视图$ {\hat{V}}_{\mathrm{a}} $中找到与其相似程度最高的第k个Patch嵌入特征($ {{F}}_{{k}}^{\text{s}} $)。公式(2)用于计算同一类别的内部图像中的Patch相似度$ \text{Sim(}{{F}}_{{j}}^{\text{t}}\text{, }{{F}}_{{k}}^{\text{s}}\text{)} $,通过交叉熵损失对匹配成功的Patch对进行知识蒸馏。$ {P} $表示所有匹配Patch对的集合,$ {{w}}_{{jk}} $表示匹配Patch的权重。最终通过公式(3)计算Patch的损失$ {\mathcal{L}}_{\text{Patch}} $。
-
监督式掩码图像建模利用图像的遮蔽增强,提升学生网络在不完整数据情况下处理特征的能力。输入学生网络的视图,通过随机选择图像块进行掩码,掩码比例在0.1~0.5之间随机选择,以增加任务的难度和多样性。具体来说,首先将输入图像$X$分割为块,并转换为嵌入向量序列,分块令牌表示为$ {X}{=\{{{x}}_{\text{1}}{,}\;{{x}}_{{2}}{,\;\cdots ,\;}{{x}}_{{i}}\text{, }{i}{=1,\;2,\;\cdots ,\;}{n}\}} $,再给定随机采样的掩码序列$ {M} $进行掩码,$ \text{|}{M}\text{|} $表示图像的分块数量,用共享的可学习令牌向量集合$ {E} $替换这些掩码位置的原始嵌入,可学习令牌序列在位置编码添加后输入网络训练,模型基于未掩码块的上下文信息预测被掩码块的特征表示。损坏的图像$ \hat{X} $包含未遮蔽和遮蔽的分块输入学生网络,$ \odot $表示逐元素乘法,公式(4)用于计算损坏的图像$ \hat{X} $。接着使用$ {P}_{{i}}^{\mathrm{s}} $表示学生网络在掩码分块上的分类分布,使用$ {P}_{{i}}^{\mathrm{t}} $表示教师网络在未掩码图像上的分类分布,公式(5)通过教师网络和学生网络的分类分布计算交叉熵损失$ ({\mathcal{L}}_{\text{SMIM}}) $。最后,通过最小化$ {\mathcal{L}}_{\text{SMIM}} $的损失值,使学生网络能够学习到更有意义的特征表示。
-
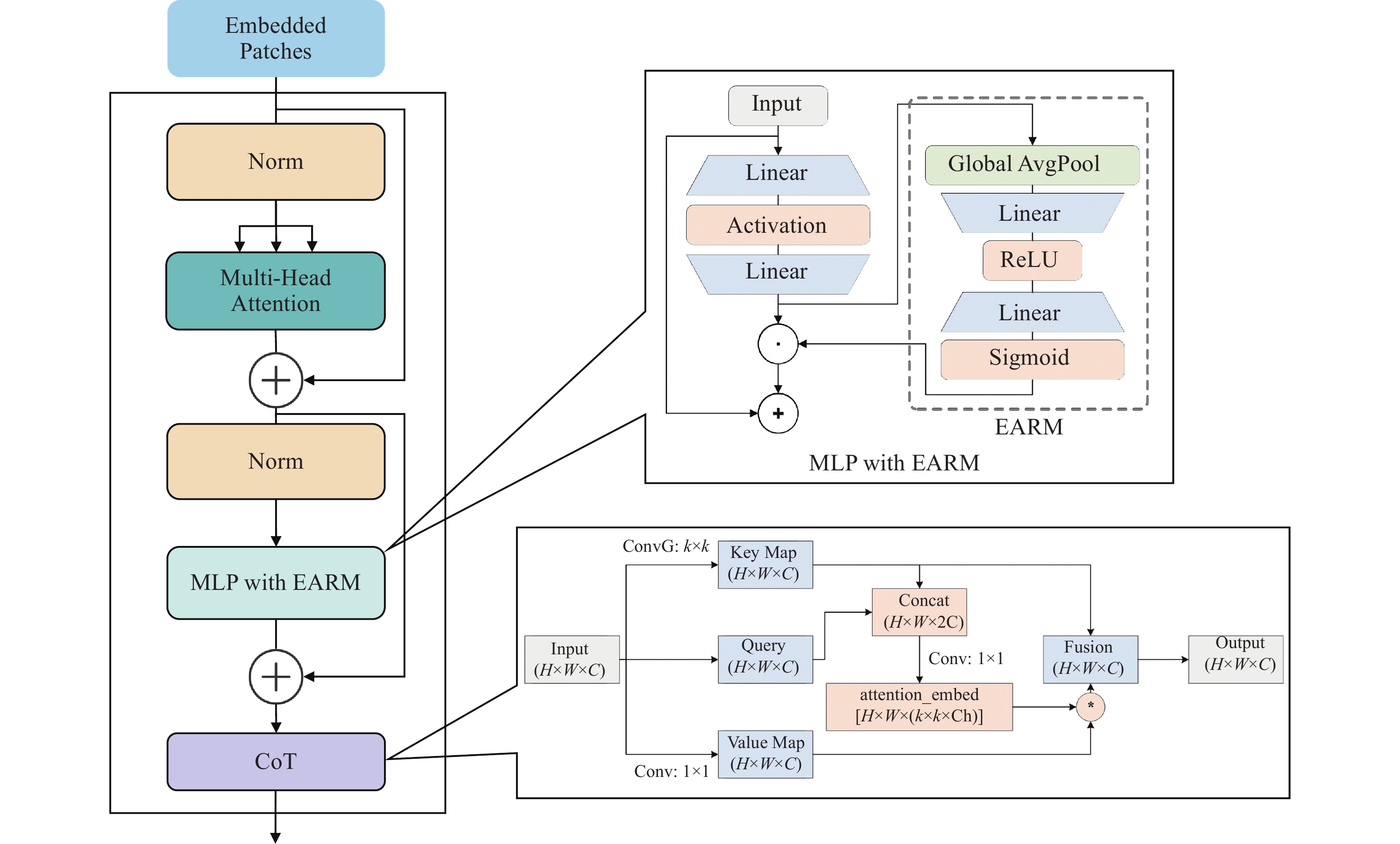
本研究提出一种基于多层感知机(MLP)和上下文转换模块(CoT)[21]的编码器优化思路,用于提升编码器在小样本学习场景下的特征表达能力和上下文建模能力。本研究在原始编码器中引入增强注意力残差模块(EARM)和CoT模块构建新型编码器ViT-EC。传统编码器的MLP层升级为MLP with EARM结构,通过SENetsqueeze-and-excitation (SENet)通道注意力机制,在特征提取初期增强模型对重要特征的表达能力;CoT模块插入ViT-EC编码器后半部分用于深层语义优化,在抽象特征层面建立全局空间和局部空间关联,增强对目标物体整体结构的感知能力。在特征提取阶段,EARM模块对输入特征标准化后,依次通过SENet通道注意力机制和增强型MLP处理,实现特征跨层传递时的动态校准。在模型的后续阶段,CoT模块利用空间维度和通道维度构建三维注意力机制,实现静态与动态上下文的结合。CoT模块首先通过1×1卷积生成Key Map和Value Map,并将原始特征投影为Query向量,利用自注意力机制计算特征块间的空间依赖权重,再与Value Map进行加权融合,最后通过1×1卷积重组通道语义与原输入双重残差连接。图3为ECKD中ViT-EC编码器架构,EARM模块在浅层网络完成通道维度的特征筛选,CoT模块在深层网络构建空间和通道的联合注意力。ViT-EC通过EARM模块和CoT模块的协同工作,不仅提升模型在小样本学习中的特征表达能力与上下文建模能力,同时还加快模型的训练速度和训练效率。
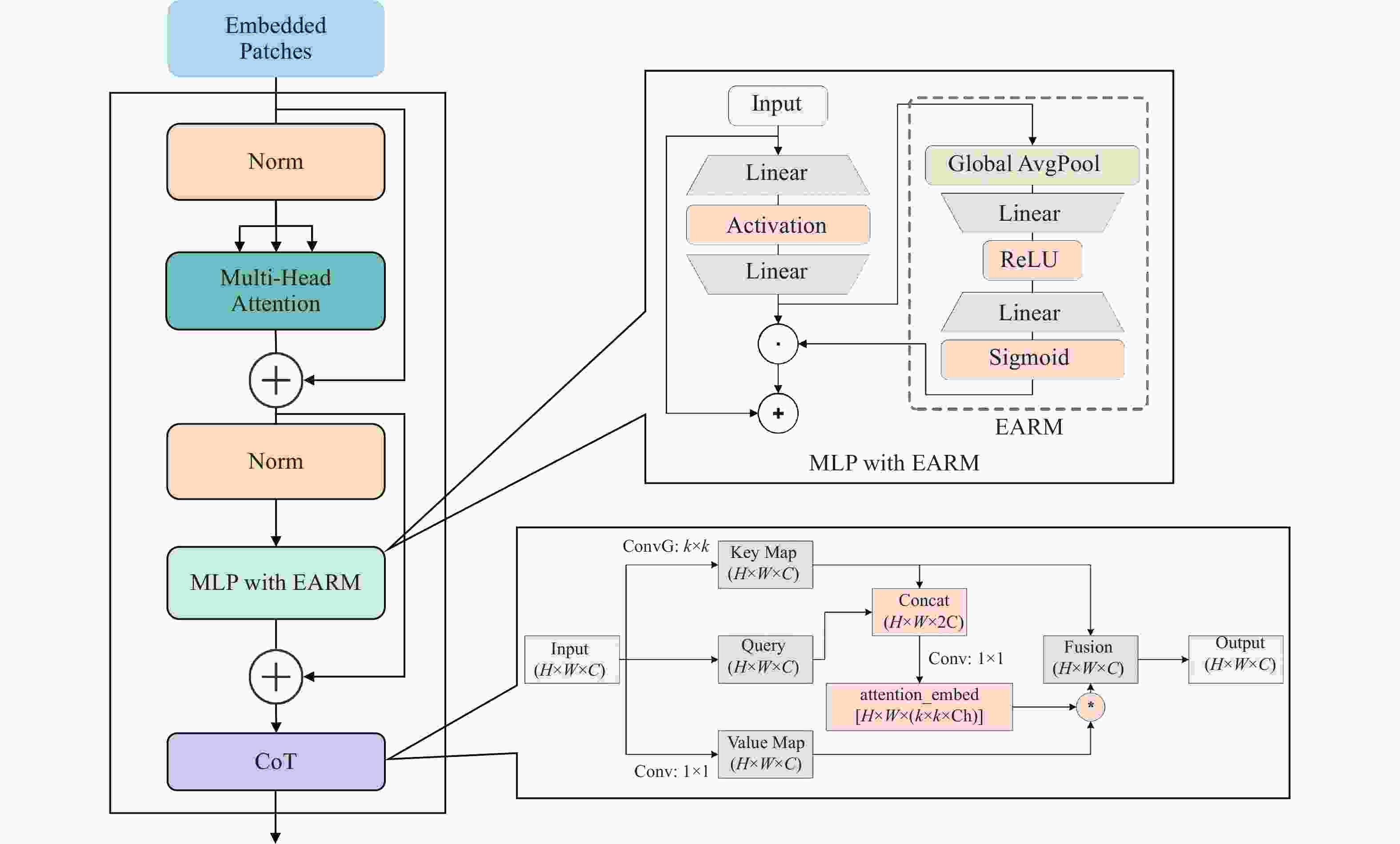
Figure 3. ViT-EC encoder
-
本研究采用原型分类器进行实验分析。原型分类器通过采取支持集的每个类别特征的均值作为该类别的原型,进而计算查询样本与各类别原型之间的相似度,从而完成类别的分类(图4)。首先从所有类别中随机选择若干类别,每个类别选取N个支持集样本(nsup)和查询集样本(nqy),通过公式(6)计算支持集样本的特征向量$ {{(}{z}}_{{i}\text{,c}}) $的均值,并作为类别的原型($ {{p}}_{\text{c}} $),紧接着计算查询样本与所有类别原型之间的余弦相似度[$ \text{CosSim}({{z}}_{\text{q}}\text{,}{{p}}_{\text{c}})] $,如公式(7)所示。最后,通过相似度最大化确定查询样本所属类别,并计算分类准确率。

Figure 4. Evaluation process of prototype classifier
-
为验证所提方法的有效性,本研究选择公开的PlantVillage数据集进行植物病害识别的实验。PlantVillage数据集对每幅图像都进行严格的筛选和标注,包含54 303幅植物叶片图像,涵盖14种植物和26种叶病,结合植物和叶病,形成38个类别(包含健康类别)。图5为PlantVillage数据集的图像类别个例,表1为PlantVillage数据集的所有作物类型和相关病害。按照数量比例为6∶4随机划分数据集类别,其中24个类别的样本作为训练集,剩余14个类别的样本作为评估集。

Figure 5. Examples of image categories in the PlantVillage dataset
植物 病害名称 数据集 序号 植物 病害名称 数据集 序号 苹果Malus pumila 黑点病 Ds 1 番茄 早疫病 Ds 20 苹果 黑腐病 Ds 2 番茄 健康 Ds 21 蓝莓Vaccinium uliginosum 健康 Ds 3 番茄 叶霉病 Ds 22 樱桃Cerasus pseudocerasus 健康 Ds 4 番茄 斑枯病 Ds 23 樱桃 白粉病 Ds 5 番茄 二斑叶螨病 Ds 24 玉米Zea mays 灰斑病 Ds 6 苹果 锈病 Dt 25 玉米 枯叶病 Ds 7 苹果 健康 Dt 26 葡萄Vitis vinifera 黑腐病 Ds 8 玉米 锈病 Dt 27 葡萄 黑痘病 Ds 9 玉米 健康 Dt 28 葡萄 健康 Ds 10 葡萄 叶枯病 Dt 29 橘子Citrus reticulata 黄龙病 Ds 11 桃子 细菌斑点病 Dt 30 桃子Prunus persica 健康 Ds 12 胡椒 健康 Dt 31 胡椒Piper nigrum 细菌斑点病 Ds 13 土豆Solanum tuberosum 早疫病 Dt 32 树莓Rubus idaeus 健康 Ds 14 土豆 健康 Dt 33 大豆Glycine max 健康 Ds 15 土豆 晚疫病 Dt 34 南瓜Cucurbita moschata 白粉病 Ds 16 番茄 晚疫病 Dt 35 草莓Fragaria ananassa 健康 Ds 17 番茄 轮斑病 Dt 36 草莓 叶焦病 Ds 18 番茄 花叶病 Dt 37 番茄Solanum lycopersicum 细菌斑点病 Ds 19 番茄 黄曲叶病 Dt 38 说明:序号所对应的植物病害见图5。Ds表示植物病害的源数据集;Dt表示植物病害的目标数据集。 Table 1. Image category information of the PlantVillage dataset
-
本研究的所有工作均基于PyTorch框架实现,所有训练和评估实验均在配备 CUDA 11.3的NVIDIA GTX-
3090 GPU上进行。CPU处理器为12th Gen Intel(R) Core(TM) i9-12900KF(3.20GHz),搭配32 GB内存,batch size为16,学习率初始设置为0.000 5,采用余弦退火调度,优化器设置为AdamW优化器。软件环境为64位Windows 10 专业版操作系统,Python 3.8 和 PyTorch 1.11。 -
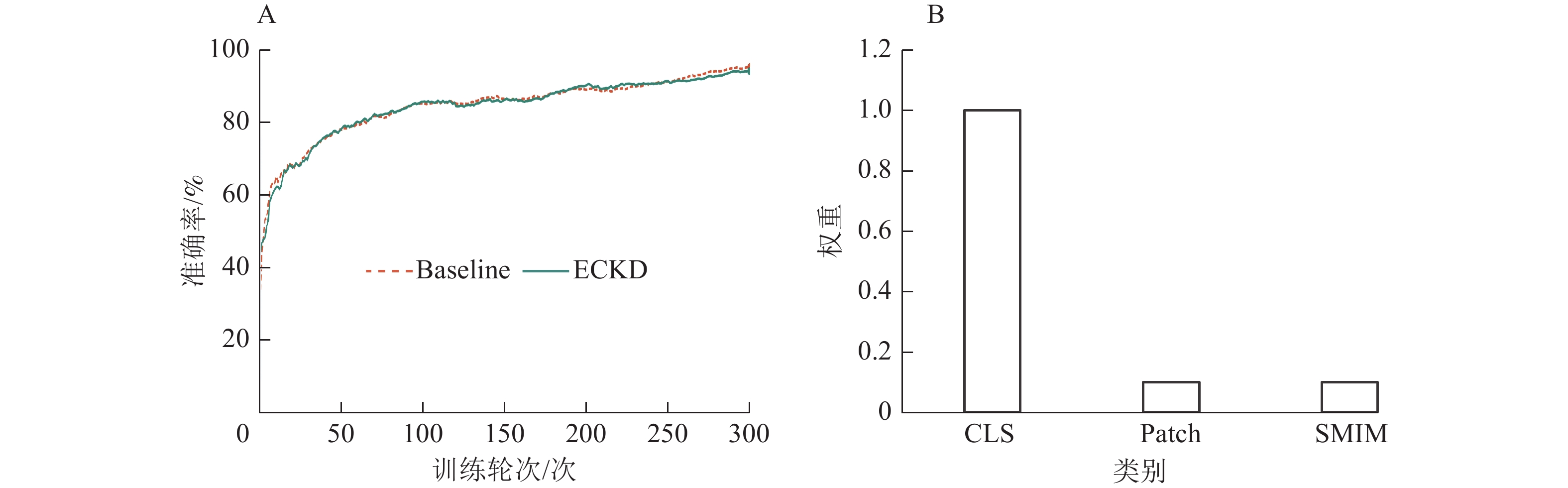
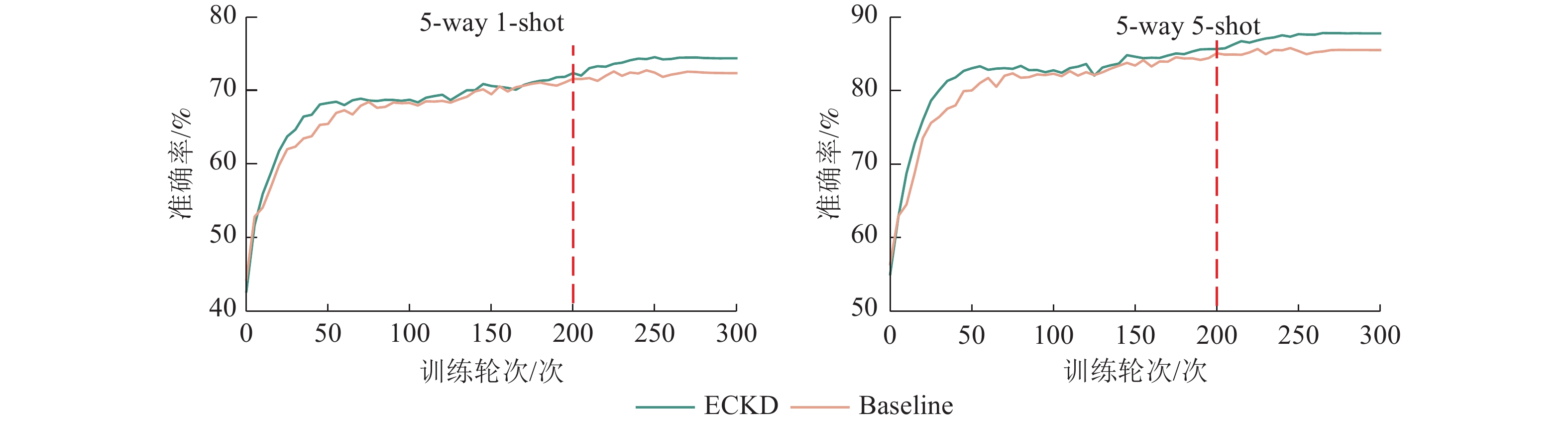
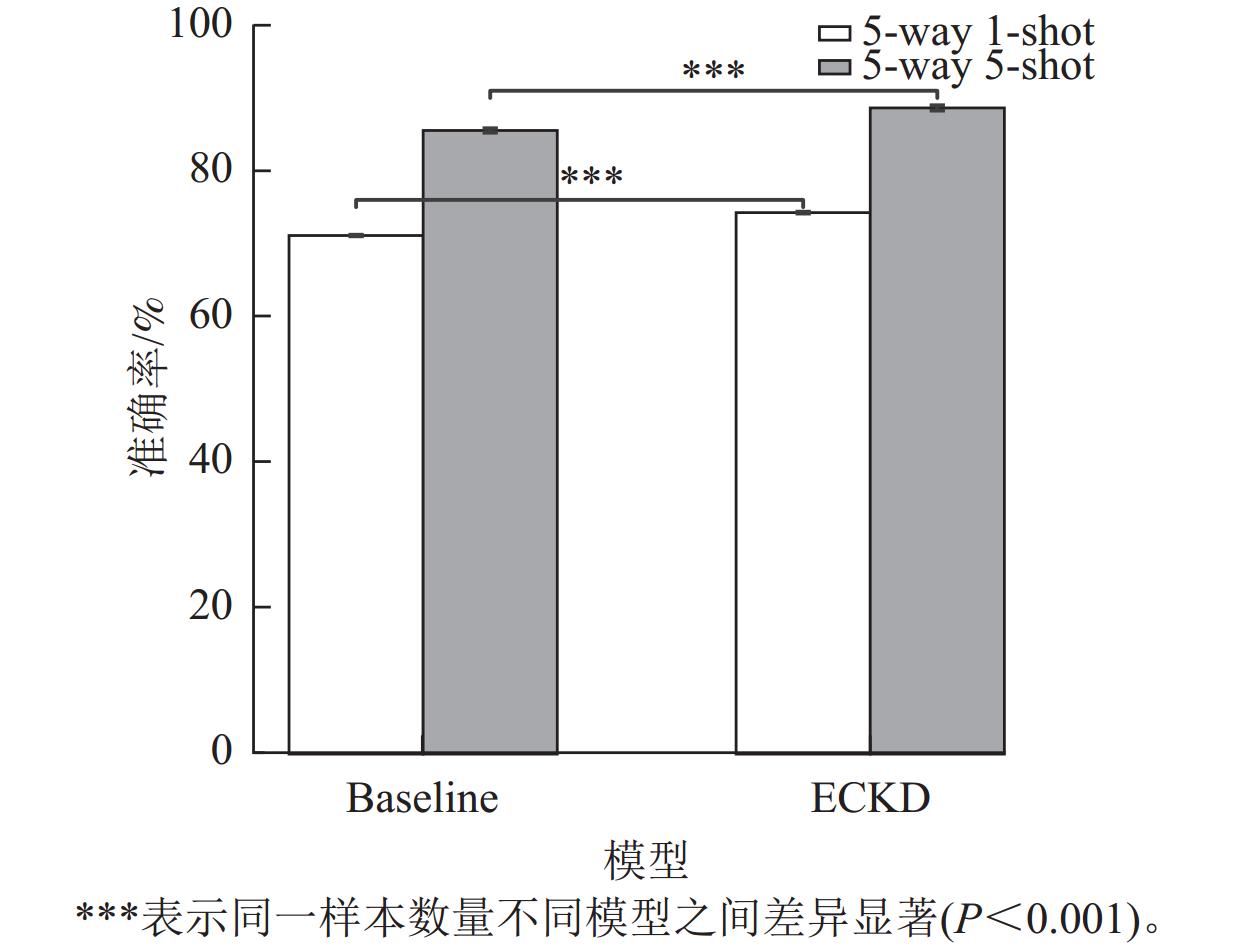
本研究采用可视化手段对ECKD模型与基线(Baseline)模型的性能进行比较。图6为ECKD的预训练情况和不同视图策略学习时设置的学习率,表明在训练的早期阶段,ECKD能够更快地达到稳定状态,在预训练时的效果比基线更好。图7为ECKD和基线在原型分类器上的准确率和训练轮次(epoch)的对比。在原型分类器方法验证中,ECKD大约在200个训练轮次就可以达到基线的效果,这比基线的预训练次数少100个训练轮次,表明ECKD方法的特征提取方式在捕捉全局信息和关键细节方面更具优势。实验设置重复运行10次小样本分类评估,计算每次运行的准确率均值和标准差。如图8所示:在2类小样本任务评估中,无论采用何种模型,增加样本数量(从5 way 1-shot提升至5 way 5-shot)都能带来明显的性能增益,且在相同的样本条件下,ECKD模型的表现始终优于基线模型(P<0.001)。
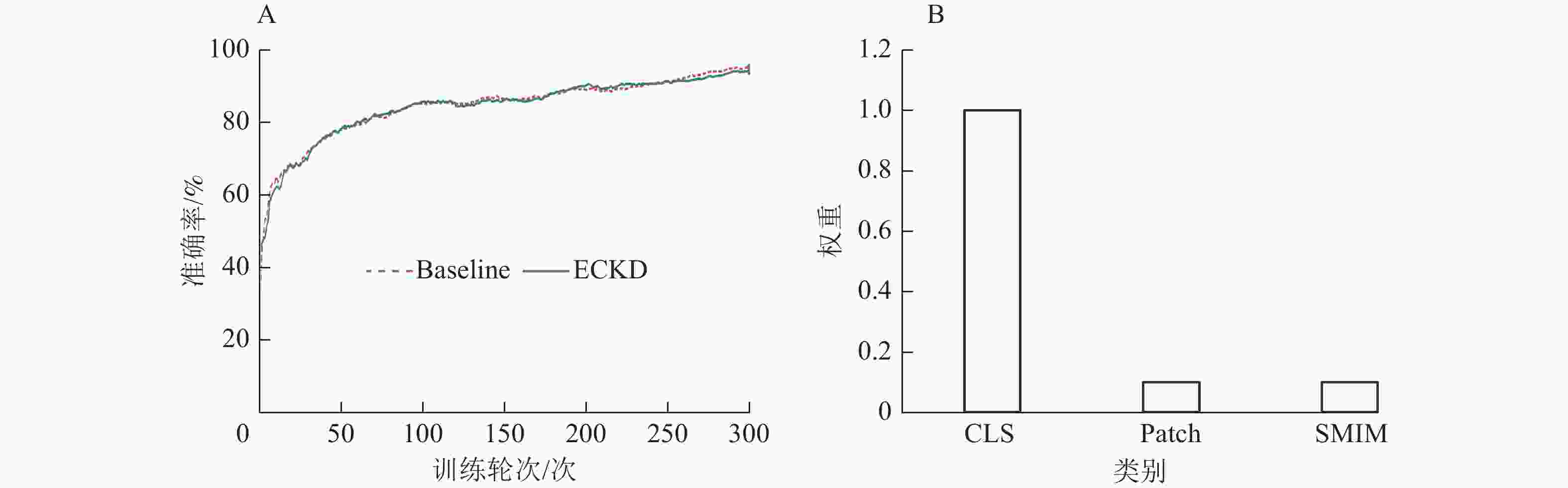
Figure 6. Training accuracy of ECKD and Baseline (A) and weight values of different loss functions (B)
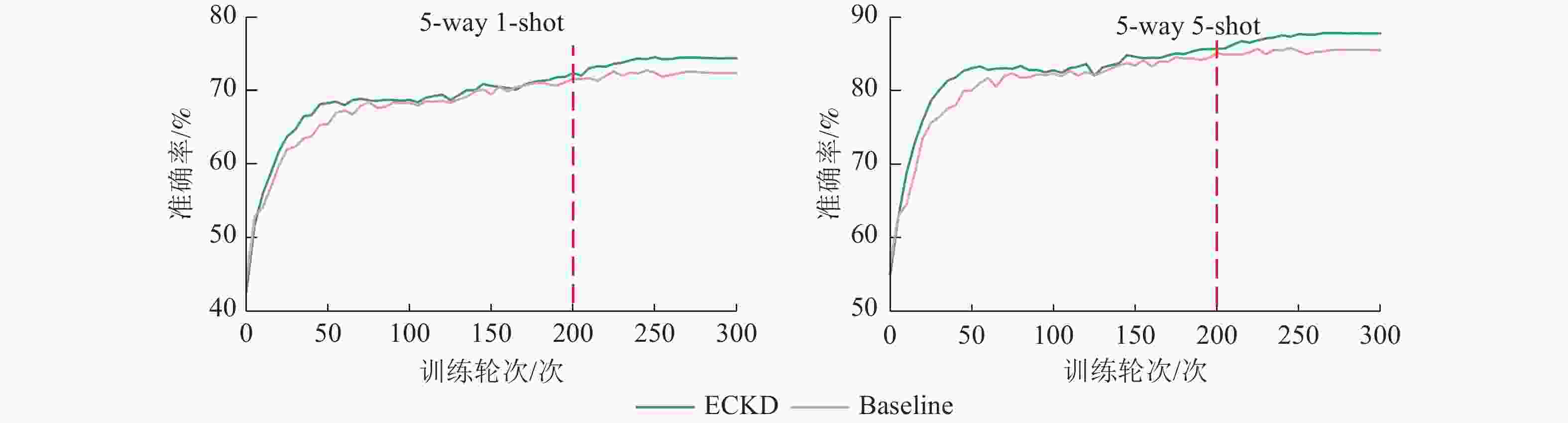
Figure 7. Accuracy of prototype classifier evaluation method in ECKD and Baseline models
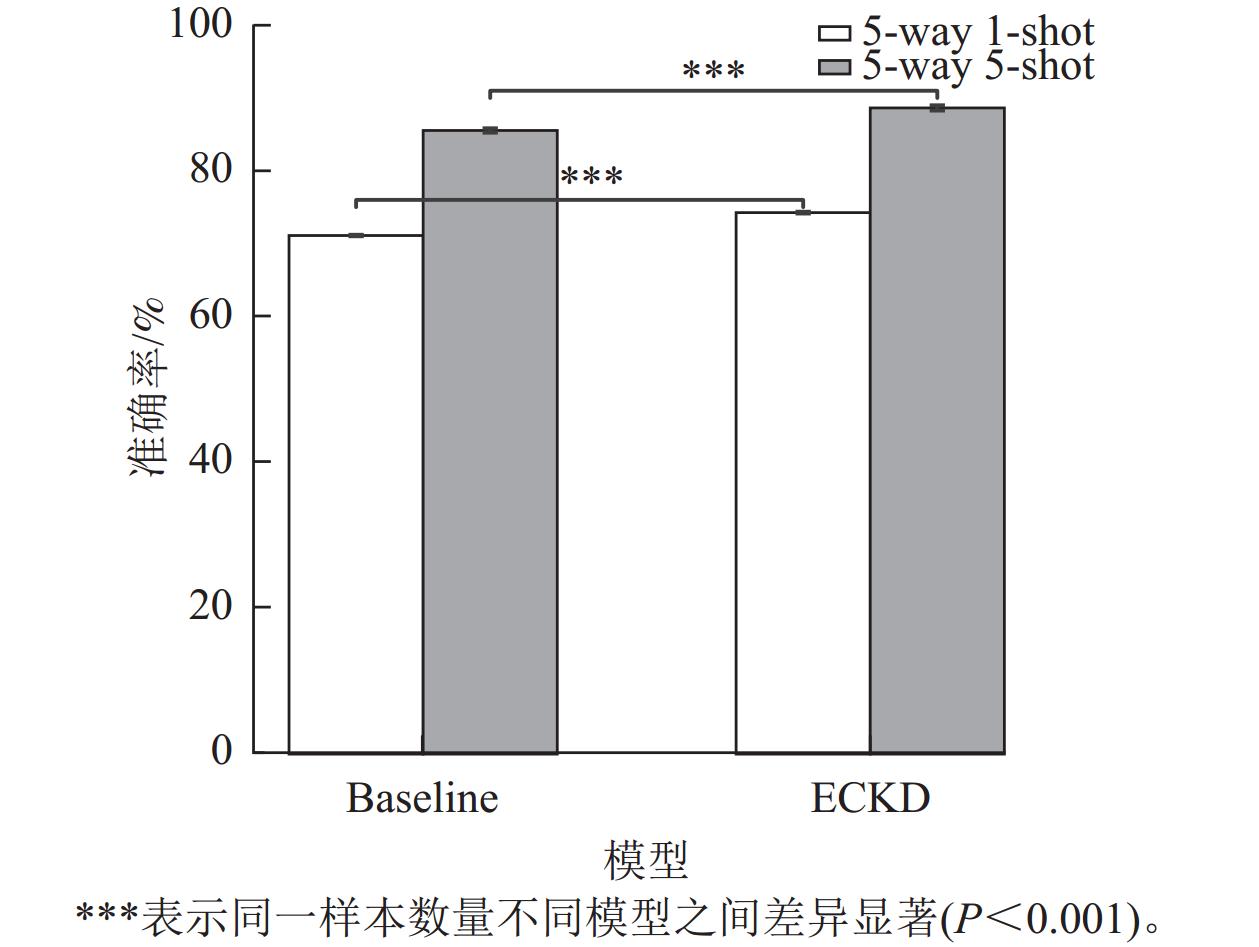
Figure 8. t-test analysis between ECKD and Baseline models
-
本研究采用ViT-S作为基线,编码器层数为12层,MLP扩展比例为4.0,输入补丁大小为16×16,采用GELU激活函数,所有实验均采用相同数据预处理与训练策略,确保对比结果的公正性与可重复性。如表2所示:ViT-S在引入EARM模块后,模型准确率有小幅度提升,表明EARM模块对局部特征的强化有助于提高目标分类的效果。在保持主干网络不变的前提下,CoT模块集成到ViT网络中进行训练,结果显示CoT模块在加强全局语境和增强特征之间的交互方面发挥了关键作用。最后,将EARM模块和CoT模块结合构成新的编码器ViT-EC,模型在5-way 1-shot和5-way 5-shot的小样本任务中准确率明显提升,表明ViT-EC在局部特征的精细表达与全局上下文的丰富性之间找到平衡,使得模型能够更好地关注关键特征。
模型 原型分类器准确率/% 5-way 1-shot 5-way 5-shot ViT-S 72.17 85.62 ViT-S + EARM 73.39 86.30 ViT-S + CoT 73.31 86.96 ViT-S + EARM + CoT 74.98(+2.81) 88.28(+2.60) 说明:括号内数值表示与ViT-S相比提升的准确率。 Table 2. Prototype classifier ablation experiment
-
由表3可见:与现有的小样本学习方法相比,ECKD明显提高了小样本学习任务中的性能。匹配网络和关系网络以及原型网络作为小样本基础方法[22],虽然在5-way 1-shot 和5-way 5-shot 任务中取得不错的结果,但在复杂数据的特征表达和上下文建模能力上存在局限性。ECKD基于更强大的Vision Transformer架构,相比最佳的基础方法,在5-way 1-shot 任务中的识别结果达74.98%,超越了小样本基础方法中的最佳结果。在5-way 5-shot任务中,ECKD的识别结果达88.28%,总体上与小样本基础方法保持持平。Iterative SS[23]和Mahalanobis[24]方法在小样本任务上准确率仅达34.00%和46.60%,难以应对复杂的小样本场景。CMSFF+CA[25]和Frequency+GC[26]以及FREN[27]利用改进后的ResNet12作为特征提取器,在5-way 1-shot和5-way 5-shot 任务中虽然取得较好的结果,但仍然难以充分建模小样本情境下的上下文关系和特征表达。基于ResNet12度量学习框架的Prune-FSL[28]虽然展示出良好的识别性能,但Prune-FSL缺乏对图像中结构性区域的显式建模,在处理复杂病斑语义关系、增强跨样本一致性及结构表征方面,ECKD展现出更强的竞争力与实用性。PMF+FA方法[29]采用ViT作为主干网络,虽然表现出良好的识别性能,但未考虑病斑在空间结构层面的完整性与边缘连续性,ECKD引入的SMIM策略通过掩码学习增强模型对局部结构区域的感知能力,从而在背景干扰严重时依然能有效聚焦病斑核心区域。虽然Transformer系列(PMF+FA和ECKD)在参数量方面略高,但其计算量与其他方法基本保持在同一量级,而在5-way 5-shot场景下,Transformer系列对准确率的提升明显优于CNN系模型,说明ViT-EC在模型规模与计算代价可接受的前提下具备更强的特征建模能力,适合对性能有更高要求的小样本学习任务。从表4可见:ECKD与基线模型均采用ViT-S作为骨干网络,相比Baseline,ECKD参数量仅增加约6.0%,FLOPs参数量增加约6.1%,在不同样本数下均明显提升了性能。在5-way 1-shot和5-way 5-shot设置中,ECKD的性能相较于基线分别提升2.81%和2.66%,表明所提出的原型增强与特征蒸馏机制有效缓解了极少样本条件下的特征不足问题。随着样本数量的进一步增加,ECKD在5 way 10-shot和5 way 15-shot设置下准确率分别达90.97%和92.27%,呈现出良好的增长趋势,验证了所提方法在小样本学习场景中的有效性与实用价值。综合对比,ECKD通过结合Vision Transformer的全局和局部上下文建模能力和知识蒸馏框架的特性增强机制,在小样本学习任务中展现出强大的性能优势。
方法 主干网络 参数量/M 计算量/G 准确率/% 5-way 1-shot 5-way 5-shot 匹配网络 Conv4 1.55 3.87 73.19 88.91 关系网络 Conv4 1.55 3.87 73.01 85.82 原型网络 Conv4 1.55 3.87 72.25 88.30 Iterative SS CNN 6.75 3.20 34.00 53.10 Mahalanobis ResNet18 24.88 3.60 46.60 63.50 CMSFF + CA Resnet12 12.75 4.70 60.70 78.10 Frequency + GC Resnet12 12.75 4.70 64.50 80.90 FREN Resnet12 12.75 4.70 66.10 84.20 Prune-FSL ResNet12 12.75 4.70 77.17 88.86 PMF+FA ViT-S 21.67 4.24 86.79 ECKD ViT-S 23.00 4.50 74.98 88.28 Table 3. Comparison of 5-way 1-shot and 5-way 5-shot experiment of existing few shotlearning methods
模型 主干网络/M 参数量/G 计算量 准确率/% 5-way 1-shot 5-way 5-shot 5-way 10-shot 5-way 15-shot Baseline ViT-S 21.67 4.24 72.17 85.62 88.91 90.11 ECKD ViT-S 23.00 4.50 74.98 88.28 90.97 92.27 Table 4. Comparison of the few-shot classification performance between ECKD and the Baseline models
-
本研究提出了一种基于Vision Transformer和增强知识蒸馏的小样本学习框架ECKD,通过设计新型编码器和多种视图策略显著提升了模型在小样本任务中的性能。结果表明:ECKD在PlantVillage数据集上明显优于多种现有方法。本研究综合考虑全局特征和局部特征的相互影响,为小样本学习提供了新的思路和解决方案,在植物病害识别等实际应用中具有广泛的潜力。未来应重点探索先进的知识蒸馏策略,扩展数据集规模与多样性,并推进多模态小样本识别研究,进一步促进小样本学习技术在农业智能感知等实际场景中的应用与转化。
Few-shot learning for plant disease recognition with enhanced knowledge distillation
doi: 10.11833/j.issn.2095-0756.20250325
- Received Date: 2025-04-07
- Accepted Date: 2025-07-03
- Rev Recd Date: 2025-07-02
- Available Online: 2025-08-01
- Publish Date: 2025-08-01
-
Key words:
- plant disease identification /
- few-shot learning /
- knowledge distillation /
- view strategy /
- prototype classifier
Abstract:
| Citation: | NIE Yuan, ZHOU Houkui, ZHANG Guangqun, et al. Few-shot learning for plant disease recognition with enhanced knowledge distillation[J]. Journal of Zhejiang A&F University, 2025, 42(4): 667−676 doi: 10.11833/j.issn.2095-0756.20250325

|


 DownLoad:
DownLoad: