





-
随着第2代测序技术的发展,转录组测序(RNA-Seq)已成为植物分子生物学研究的重要手段,广泛应用于功能基因挖掘、分子标记开发、代谢通路和调控机制研究等方面[1-3]。该技术具有成本低、数据量大、效率高、准确性高等优点[4],可对组织或者细胞中所有RNA进行测序,并通过读段(reads)的拼接和丰度统计获得相应的转录本序列信息及其表达水平[5]。云锦杜鹃Rhododendron fortunei为杜鹃花科Ericaceae杜鹃花属Rhododendron植物,为中国特有种,主要分布于安徽、湖南、湖北、浙江等省[6]。云锦杜鹃叶形大,花形美丽具清香,具有较高的园艺观赏价值;适应性较强,易人工栽培,也常作为杜鹃属种间杂交的亲本;此外,枝叶等组织中含有槲皮素、山柰酚、杨梅素等有效活性成分,可开发入药[7-8]。可见,云锦杜鹃作为一种兼具观赏价值和药用价值的优良木本花卉,开发潜力巨大,具有良好的产业化前景。目前,云锦杜鹃的研究主要集中在野生资源调查[9]、群落结构[10]、无性繁殖技术[11]、有效成分分析[8, 12]、光合特性[13]、菌根共生等方面[14]。由于缺乏遗传信息,云锦杜鹃的遗传多样性、分子辅助育种等的研究较为滞后。本研究通过RNA-seq高通量测序技术对云锦杜鹃转录组进行测定,通过序列拼接、功能注释和分析,获取大量的序列信息,旨在为云锦杜鹃分子标记开发,遗传多样性分析,以及功能基因挖掘、重要性状形成分子机制等研究提供序列信息。
HTML
-
前期以天台华顶林场云锦杜鹃优株茎段为外植体,通过组培获得云锦杜鹃无性系ZL-01。以该无性系组培苗为材料,取其嫩叶、嫩茎和根,液氮冷冻后保存于-80 ℃用于RNA提取。
-
采用Trizol试剂(Invitrogen),按照试剂说明书分别提取组培苗根、茎、叶的总RNA。采用Agilent 2100 Bioanalyzer(Agilent),对总RNA样品的纯度、浓度和完整性进行检测评估,等量混合后用于测序文库构建。
-
取检验合格的RNA,用带有Oligo(dT)的磁珠富集mRNA,将得到的mRNA随机打断成短片段,用六碱基随机引物合成一链cDNA,然后加入缓冲液、dNTPs、DNA polymerase I和RNase H合成二链cDNA。双链cDNA经纯化后进行末端修复,加ploy(A)并连接测序接头,通过PCR扩增及纯化后得到测序文库。采用Illumina Hiseq 2500进行转录组的测序,测序由北京诺禾致源生物公司完成。
-
针对测序得到的原始数据(raw data)进行接头和低质量测序片段(reads)去除等处理,获得高质量的干净数据(clean data);计算干净数据的Q20和Q30,GC含量和碱基错误率,评估测序质量;利用序列的重叠,通过Trinity软件对干净数据数据进行序列组装,将短测序片段延伸成较长的片段,并得到片段集合,利用De Bruijin方法[15]得到转录本(transcripts)和单基因簇(unigene)序列。
-
利用BLAST和HMMER软件将云锦杜鹃单基因簇序列与公共数据库进行比对,根据基因的相似性进行功能注释,得到与给定单基因簇具有最高序列相似性的蛋白,从而得到该单基因簇的蛋白功能注释信息,其中BLAST参数E≤1e-5,HMMER参数E≤1e-10作为筛选标准。比对采用的公共数据库包括美国生物信息中心(NCBI)非冗余蛋白数据库(Non-redundant protein database,Nr),NCBI核酸序列数据库(Non-redundant nucleotide sequences,Nt),蛋白质序列数据库(Swiss Prot protein database,SwissProt),真核直系同源基因数据库(Eukaryotic orthologous groups,KOG),蛋白质家族数据库(Protein families database,Pfam),基因本体论数据库(Gene ontology,GO)及京都基因与基金组百科全书(Kyoto encyclopedia of genes and genomes,KEGG)。
-
采用MISA软件对云锦杜鹃单基因簇进行简单序列重复(SSR)分析,鉴定其中6种类型的SSR;各SSR类型重复次数设定为:单核苷酸SSR,重复数≥10次;二核苷酸SSR,重复数≥6次;三至六核苷酸SSR,重复数≥5次。
1.1. 植物材料
1.2. RNA提取与质控
1.3. 测序文库构建
1.4. 转录组数据分析
1.5. 基因功能注释
1.6. SSR分析
-
分别提取无性系ZL-01组培苗根、茎和叶的RNA。检测结果表明:根RNA的质量浓度为362 mg·L-1,28S/18S为1.6,RNA完整性计数(RNA integrity number,RIN)为9.6;茎RNA的质量浓度为515 mg·L-1,28S/18S为1.8,RIN值为9.8;叶RNA的质量浓度为485 mg·L-1,28S/18S为1.8,RIN值为9.7。这些指标均符合建库测序要求,因此,将这3个组织的RNA等量混合后进行测序。
测序数据经处理后得到94 252 430个干净测序片段(clean reads),包含了14.14 Gb核苷酸序列信息,GC含量为47.58%。测序质量评估结果显示,碱基错误率为0.02%,Q20为96.70%,Q30为91.85%。这些表明该转录组的数据量和质量均较高,为后续的序列组装提供了高质量的原始数据。
通过Trintiy软件组装得到112 777个转录本,总长度为91 621 682 bp,平均长度为812.4 bp,N50为1 410,其中长度在1 kb以上的有29 225条,占25.92%;2 kb以上的10 418条,占9.24%(表 1)。对转录本进行聚类和组装得到84 633个单基因簇,总长度为58 517 298 bp,平均长度为691.4 bp,N50为1 177 bp;其中超过1 kb的有16 631条,占19.65%;超过2 kb的5 760条,占6.81%(表 1)。
长度范围/bp 转录本/个 单基因簇/个 <301 35 575(31.54) 32 101(37.93) 301~500 25 511(22.62) 20 759(24.53) 501~1 000 22 466(19.92) 15 142(17.89) 1 001~2 000 18 807(16.68) 10 871(12.84) >2 000 10 418(9.24) 5 760(6.81) 总数 112 777 84 633 总长度 91 621 682 58 517 298 N50长度 1 410 1 177 平均长度 812.4 691.4 说明:括号内数值为占总数的百分比(%) Table 1. Summary of transcriptome assembly for R. fortunei
-
将单基因簇序列与Nr,Nt,SwissProt,GO,KOG,KEGG和Pfam 7个数据库进行比对,共有35 526条单基因簇获得成功注释,占单基因簇的41.97%(表 2)。其中,30 700条单基因簇获得Nr数据库注释,占36.27%;23 215条单基因簇获得GO数据库注释,占27.43%;22 882条单基因簇获得Pfam数据库注释,占27.03%;22 202条单基因簇获得Swiss-prot数据库注释,占26.23%;18 046条单基因簇获得Nt数据库注释,占21.32%;11 085条单基因簇获得KOG数据库注释,占13.09%;9 887条单基因簇获得KEGG数据库注释占11.68%(表 2)。
数据库 被注释的单基因簇/条 百分比/% Nr 30 700 36.27 KEGG 9 887 11.68 Nt 18 046 21.32 SwissProt 22 202 26.23 Pfam 22 882 27.03 GO 23 215 27.43 KOG 11 085 13.09 总计 35 526 41.97 Table 2. Annotation of unigenes in transcriptome of R. fortunei
在Nr库中,云锦杜鹃转录组注释到其他物种的单基因簇基因序列共30 700条。其中与葡萄Vitis vinifera基因序列相似的最多,所占比例为24.39%;其次为中粒咖啡Coffea canephora,所占比例为7.39%;第3为可可Theobroma cacao,占6.77%;其他相似性序列数量大于3%的物种有烟草Nicotiana tomentosiformis(6.19%),毛果杨Populus trichocarpa(4.09%),甜橙Citrus sinensis(3.82%),麻疯树Jatropha curcas(3.76%)和梅花Prunus mume(3.16%),其他物种占40.43%(图 1)。

Figure 1. Similarity of unigenes of R. fortunei with those of other species in Nr database
-
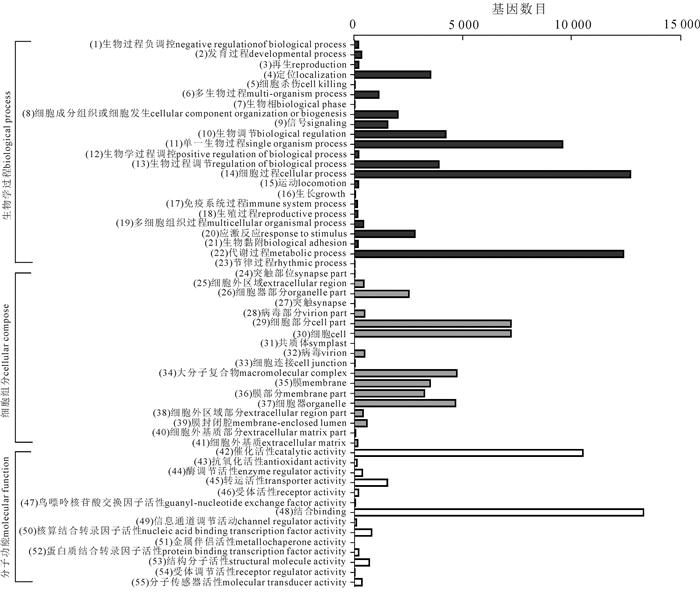
通过GO数据库的注释,共有23 215条单基因簇获注释信息,得到119 389个GO功能注释。由分类结果可知:生物学过程(biological process)最多55 692条,占46.65%,其次是细胞组分(cellular component),35 577条,占29.80%,最少的分子功能(molecular function),有28 120条,占23.55%;这三大功能分类又可分为55个亚类,其中生物学过程23个亚类,细胞组分18个亚类,分子功能14个亚类(图 2)。生物学过程中,涉及细胞过程、代谢过程和单一有机体进程的单基因簇较多,分别有12 698,12 376和9 581条;细胞组分中涉及较多的是细胞、细胞部分和大分子复合体,分别有7 216,7 214和4 713条;分子功能中涉及较多的有结合功能和催化活性,分别有13 302,10 524条(图 2)。

Figure 2. GO functional categories of R. fortunei unigenes
-
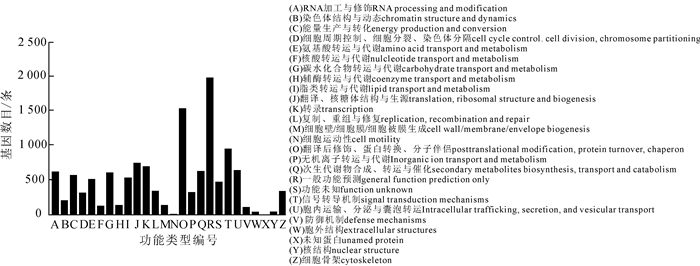
通过KOG数据库对云锦杜鹃单基因簇进行注释,结果显示有11 085条序列获得12 475个注释信息,可分为26个功能分类(图 3)。从基因功能分类来看,涉及一般功能预测的序列最多,多达1 970条;涉及翻译后修饰、蛋白翻转、分子伴侣功能的序列次之,有1 527条;而涉及核结构、胞外结构和细胞运动的序列很少,仅有37,34和5条(图 3)。

Figure 3. KOG functional categories of R. fortunei unigenes
-
利用KEGG注释系统对云锦杜鹃单基因簇涉及的代谢途径进行分析,结果显示:9 887条单基因簇得到15 455个注释,归属于272条通路。按获得注释的基因数量进行排序,取前20个途径,发现含有200条单基因簇以上的通路有10个,涉及碳代谢的单基因簇最多,有377条;其次是与核糖体相关的单基因簇,有364条;第3位是与氨基酸合成相关的单基因簇,有348条;涉及其他途径有内质网蛋白加工(319)、剪切体(256)、植物激素信号转导(244)、淀粉和蔗糖代谢(240)、RNA转运(227)、氧化磷酸化(224)和植物病原物相互作用(210);其他通路的单基因簇数量均在200以下(表 3)。
KEGG通路 通路ID 单基因簇/条 碳代谢carbon metabolism ko01200 377 核糖体ribosome ko03010 364 氨基酸合成biosynthesis of amino acids ko01230 348 内质网蛋白加工protein processing in endoplasmic reticulum ko04141 319 剪切体spliceosome ko03040 256 植物激素信号转导plant hormone signal transduction ko04075 244 淀粉和蔗糖代谢starch and sucrose metabolism ko00500 240 RNA转运RNA transport ko03013 227 氧化磷酸化oxidative phosphorylation ko00190 224 植物病原物互作plant-pathogen interaction ko04626 210 内吞作用endocytosis ko04144 194 嘌呤代谢purine metabolism ko00230 193 糖酵解途径glycolysis / gluconeogenesis ko00010 184 泛素介导蛋白降解ubiquitin mediated proteolysis ko04120 174 mRNA监测通路mRNA surveillance pathway ko03015 171 苯丙素生物合成phenylpropanoid biosynthesis ko00940 169 细胞周期cell cycle ko04110 168 氨基糖和核苷酸糖代谢amino sugar and nucleotide sugar metabolism ko00520 160 嘧啶代谢pyrimidine metabolism ko00240 148 RNA降解RNA degradation ko03018 146 说明:注释数量总数为15 455 Table 3. Summary KEGG pathway of R. fortunei transcriptome
-
MADS-box基因家族在植物花分生组织形成、花器官发育等过程中发挥关键作用[16]。鉴定转录组中的MADS-box基因有助于进一步研究或调控云锦杜鹃成花过程。通过与Nr,Nt和Swiss-prot三大数据库比对,共找出编码MADS-box基因的单基因簇序列24条,分别属于10个不同的亚家族(表 4)。其中AGL17亚家族成员最多,包含c41091_g4,c39737_g1,c36841_g1,c38538_g1和c40334_g4;SQUA和SVP亚家族则各有4个成员,分别为c50592_g1,c10093_g1,c9572_g1,c2583_g1与c37773_g1,c31351_g1,c30064_g1,c33061_g2;TM3亚家族有3个成员,其他亚家族仅有2个或1个成员(表 4)。这些单基因簇的同源基因分别与花分生组织发育、花期调控、花器官发育、果实发育等重要生物学过程相关。
序列号 注释 功能 亚家族 c18022_g1 Agamous-like MADS-box protein AGL15 雄蕊,心皮,胚珠和果实发育;花分生组织发育 AG c70492_g1 Agamous-like MADS-box protein AGL12 花期转变 AGL12 c12164_g1 Agamous-like MADS-box protein AGL15 胚胎发育 AGL15 c41091_g4 MADS-box transcription factor 27 促进开花 AGL17 c39737_g1 MADS-box transcription factor 27 促进开花 AGL17 c36841_g1 Agamous-like MADS-box protein AGL21 促进开花 AGL17 c38538_g1 MADS-box transcription factor 27 促进开花 AGL17 c40334_g4 MADS-box transcription factor 27 促进开花 AGL17 c18716_g1 Agamous-like MADS-box protein AGL3 花被发育;花分生组织发育 AGL2 c33061_g1 Agamous-like MADS-box protein AGL9 homolog 花被发育;花分生组织发育 AGL2 c29354_g1 Floral homeotic protein DEFICIENS 花瓣和雄蕊发育 DEF c32438_g1 Agamous-like MADS-box protein AGL31 花期调控;成花抑制 FLC c37758_g1 MADS-box protein FLOWERING LOCUS C 花期调控;成花抑制 FLC c50592_g1 Agamous-like MADS-box protein AGL8 homolog 萼片和花瓣发育;花分生组织发育;果实发育;花期调控 SQUA c10093_g1 Agamous-like MADS-box protein AGL8 homolog 萼片和花瓣发育;花分生组织发育;果实发育;花期调控 SQUA c9572_g1 Agamous-like MADS-box protein AGL8 homolog 萼片和花瓣发育;花分生组织发育;果实发育;花期调控 SQUA c2583_g1 Agamous-like MADS-box protein AGL8 homolog 萼片和花瓣发育;花分生组织发育;果实发育;花期调控 SQUA c37773_g1 MADS-box protein SVP 花期调控;成花抑制和激活 SVP c31351_g1 MADS-box protein SVP 花期调控;成花抑制和激活 SVP c30064_g1 MADS-box protein JOINTLESS 花期调控;成花抑制和激活 SVP c33061_g2 MADS-box protein SVP 花期调控;成花抑制和激活 SVP c73448_g1 MADS-box transcription factor 56 花期调控;成花激活 TM3 c20770_g1 MADS-box transcription factor 50 花期调控;成花激活 TM3 c5966_g1 MADS-box protein SOC1 花期调控;成花激活 TM3 Table 4. Identification of Floral related MADS-box genes of R. fortunei
-
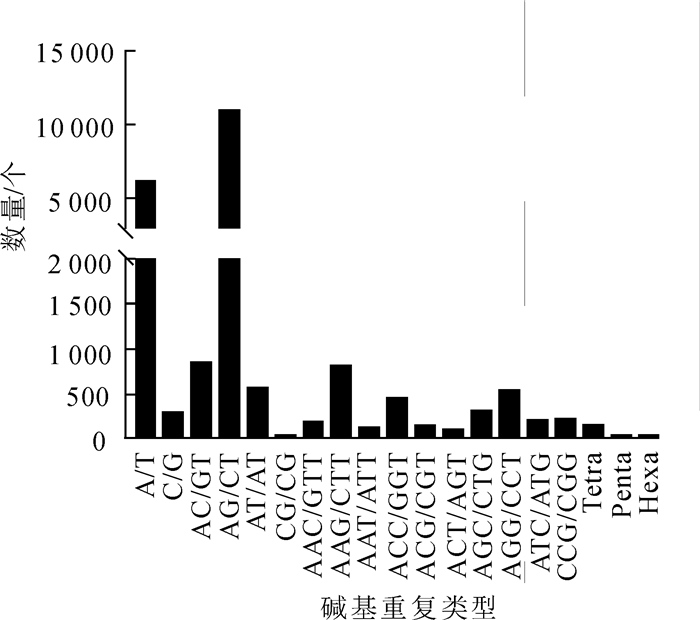
利用MISA软件对云锦杜鹃转录组序列进行分析,共发现21 900个SSR位点,分布在17 414条单基因簇中,其中有含有1个以上SSR位点的单基因簇有3 606条(表 5)。在所有SSR位点中,双碱基重复SSR最多,有12 294个,占总数的56.14%;其次为单碱基重复SSR,有6 448个,占总数的29.44%;三碱基重复SSR有2 970个,占13.56%;四碱基重复SSR有140个,占0.63%;五碱基和六碱基重复SSR分别仅有25个和23个(表 5)。进一步分析这些SSR重复基序,可以发现,在单碱基SSR中,A/T发生频率最高;双碱基SSR中,发生频率最高的是AG/CT,其次是AC/GT;三碱基重复中发生频率最高是AAG/CTT,其次是AGG/CCT(图 4)。
搜索项目 数量/个 分析序列数量total number of sequences examined 84 633 分析序列长度total size of examined sequences(bp) 58 517 298 SSR位点总数total number of identified SSRs 21 900 包含SSR位点序列数number of SSR containing sequences 17 414 包含1个以上SSR位点序列数number of sequences containing more than 1 SSR 3 606 复合形式存在的SSR位点数number of SSRs present in compound formation 1 437 单碱基重复mono-nucleotide 6 448 二碱基重复di-nucleotide 12 294 三碱基重复tri-nucleotide 2 970 四碱基重复tetra-nucleotide 140 五碱基重复penta-nucleotide 25 六碱基重复hexa-nucleotide 23 Table 5. Summary of SSR in R. fortunei transcriptome

Figure 4. Distribution of SSR motif number of R. fortunei
2.1. 测序结果与组装
2.2. 基因功能注释
2.3. 单基因簇的GO功能分类
2.4. 单基因簇的KOG功能注释
2.5. KEGG通路注释
2.6. MADS-box基因家族分析
2.7. SSR分析
-
中国是世界上杜鹃花属植物资源最为丰富的国家,为世界杜鹃花育种做出了巨大贡献。但中国杜鹃花育种尤其常绿杜鹃育种水平较欧美、日本等国仍有较大差距,资源开发利用水平低,优良品种少。云锦杜鹃作为中国特有常绿杜鹃,观赏价值高、抗性好,野生资源也较为丰富,具有良好的开发潜力。但由于缺乏相关的遗传背景信息,云锦杜鹃的遗传多样性、杂交子代鉴定和优异基因型挖掘等遗传育种研究一直受到制约。近年来,随着高通量测序技术的发展,转录组测序已成为非模式生物遗传背景解析的重要手段,在标记开发、表达分析、功能基因挖掘等方面得到广泛应用[17-21]。本研究利用Illumina测序技术对云锦杜鹃组培苗的转录组进行测序和分析,以获得其转录组序列信息。云锦杜鹃转录组的测序数据分析结果表明:数据的Q30值为91.85%,拼接后共获得84 633条单基因簇,平均长度为691.4 bp,N50值为1 177 bp。一般认为Q30在80%以上就认为测序质量可靠;N50值越大就表示长片段越多,且不小于800 bp就说明组装得到序列完整性较好[22]。上述结果表明本研究测序数据的质量和组装长度达到了转录组分析的基本要求,为进一步分析利用奠定了基础。
基因功能注释是转录组分析的重要内容,是进行重要功能基因挖掘的前提。因此,本研究利用Nr和Swiss-prot等七大数据库对云锦杜鹃转录组序列进行功能注释,结果表明:共有35 526条单基因簇获得注释信息,仍有约5万条序列没有获得注释。这与薏苡Coix lachryma-jobi[20]和岩穴蕨Monachosorum maximowiczii[23]的情况类似,可能是由于云锦杜鹃是未测序物种,在相关数据库中缺乏对应的功能注释信息,也可能是部分云锦杜鹃单基因簇序列本身太短造成的。GO和KOG注释功能分类的结果显示,云锦杜鹃单基因簇的功能涉及了各类生命活动;KEGG通路注释到9 887条单基因簇,涉及到272条代谢通路。这些结果表明:对于云锦杜鹃等这一非模式植物,转录组测序可以有效地解析遗传背景,获得大量序列信息。基因功能注释也是挖掘与特定途径或功能相关基因的有效手段。如在紫色黄秋葵Abelmoschus esculentus中,通过转录组的KEGG注释,获得与花色素苷、黄酮、类黄酮、二萜类和萜类骨架等生物合成相关的单基因簇[24]。本研究通过功能注释,也鉴定获得24个编码MADS-box基因的单基因簇,属于10个不同的亚家族,它们可能与花分生组织发育、花期调控、花器官发育等重要成花过程相关。
简单序列重复(SSR)又称微卫星序列,具有共显性、密度大、信息量丰富等优势,广泛应用于遗传图谱构建、遗传多样性分析、基因定位、分子标记辅助育种等方面[25]。利用转录组序列开发SSR标记具有通量高,成本低的优势,已在多种植物中获得成功[19, 26-27]。在大王杜鹃R. rex转录组序列中鉴定获15 314个SSR位点,占比最高的为双碱基重复SSR,其次为单碱基重复SSR和三碱基重复SSR,且利用这些SSR位点开发了相应引物对20份大王杜鹃种质进行了遗传多样性评价[3]。本研究也在云锦杜鹃单基因簇序列中鉴定获得21 900个SSR位点,发现其中双核苷酸重复SSR最多,达到12 294个;其次为单核苷酸重复和三核苷酸重复SSR,这与大王杜鹃中发现的规律类似。这些结果将为云锦杜鹃SSR标记开发提供重要序列信息,也为云锦杜鹃种质资源遗传多样性分析、功能基因挖掘以及分子辅助育种等工作提供了重要基础。
 DownLoad:
DownLoad: