








-
随着中国天然林全面禁伐,木材资源供给愈发紧张[1],这对木材高效识别与利用提出了更高的要求。木材识别能够维护消费者的利益,同时在合理利用木材方面发挥着一定的作用。近几年国内外木材无损检测技术主要有应力波、阻抗仪、超声波检测和X射线检测等方法。但是这些检测手段主要用于检测木材的材性和缺陷[2-7],在树种识别方面应用的较少。BARMPOUTIS等[8]利用木材横断面图像结合多维纹理分析技术和支持向量机(SVM)进行分类,识别率达91.47%。但此方法需要获取树木木材样本的横断面图像,不能完全达到无损检测的目的。ROJAS等[9]使用可听范围的应力波对树种进行了识别,这是一种无损识别方法,但仪器的布线、样本点间的测距等前期准备工作需要一定时间,不能对大批量样本的树种检测。可见/近红外光谱技术是一项无损检测技术,采谱时无需对样品进行预处理,可以达到无损检测的目的,并且单次采谱时间非常短,可以实现野外实时检测[10]。近几年国内近红外光谱技术在石油和农业上使用较多,对木材进行识别的研究还较少[11-12]。且木材样本都是解析木,导致后期识别的未知样本也需要相同规格的解析木。中国东北地区既有大、小兴安岭和长白山等茂密的天然林,又有东北各省各地区林场等密集的次生林[13]。本研究使用可见/近红外光谱识别技术,结合生长锥取样的方法,通过S-G平滑滤波、导数、Norris导数滤波等方法对光谱进行预处理,使用距离法建立了木材识别模型,识别了东北地区14种常见树种的木材。为可见/近红外光谱识别技术的预处理方法选择和平滑处理参数选择提供参考,为快速、准确识别木材提供了一种新的无损检测方法。
HTML
-
所用样品均采自黑龙江省方正县林业局星火林场(45°43′5.73″N,129°13′34.37″E)。样品由生长锥钻取,钻孔方位为由南向北穿过树心,高度为距离地面1.3 m胸高处。从25块样地选择14个树种(表 1)。采样25株·种-1,共300个样品。样品直径约5.15 mm。将样品放在温度为20 ℃,湿度为38%的室内阴干1周,使其达到气干状态。从中部截断样品用于采集光谱,为得到较稳定的模型,每个断面用80目的砂纸打磨5次,使其表面粗糙度参数Ra接近12.5 μm。在建立木材识别模型时,表面粗糙度对模型影响很小[14]。
编号 树种 材种 边材颜色 1 白桦Betula platyphylla 阔叶散孔材 黄白略带褐色 2 糠椴Tilia mandshurica 阔叶散孔材 黄红褐色 3 紫椴Tilia amurensis 阔叶散孔材 黄红褐色 4 枫桦Betula costata 阔叶环孔材 白色至浅黄色 5 云杉Picea asperata 针叶树材 浅黄褐色 6 胡桃楸Juglans mandshurica 阔叶半环孔材 浅黄褐色 7 冷杉Abies fabri 针叶树材 浅黄白略带褐色 8 红松Pinus koraiensis 针叶树材 浅黄褐色带红 9 槐树Sophora japonica 阔叶环孔材 黄色或浅灰褐色 10 水曲柳Fraxinus mandshurica 阔叶环孔材 黄白浅黄褐色 11 杨树Populus 阔叶环孔材 浅黄褐色或灰褐色 12 榆树Ulmus pumila 阔叶散孔材 黄褐色 13 蒙古栎Quercus mongolica 阔叶环孔材 浅黄褐色 14 落叶松Larix gmelinii 针叶树材 黄褐色 Table 1. Sample information
-
使用美国ASD公司生产的LabSpec光谱仪采集光谱,波长范围为350~2 500 nm。其中350~780 nm为可见光波段,780~2 500 nm为近红外波段,调整二分光纤端部距探头口2 mm处固定。采谱前将探头对准聚四氟乙烯白板进行校正,采谱过程中每15 min进行1次空白校正,以保证光谱的稳定性。将木样嵌入直径为5 mm的探头口中,光斑直径为5 mm,覆盖木样的端面,即采谱面(图 1)。每个断面采集1次光谱后旋转一定角度采集第2次光谱,共采集3次光谱,采集完成一个树种所有样本光谱后,使用OMNIC 9.2打开这些光谱,对比光谱波形相似度,筛除异常光谱后将单个样品的剩余光谱取平均光谱用于分析。用此方法采集的光谱为树木胸径处边材弦切面的光谱。用光谱仪配套的软件采集光谱并转换成数据文件,使用OMNIC 9.2,Matlab和Excel完成对光谱的初筛、预处理和数据处理工作。

Figure 1. Near infrared (NIR) collecting method for the increment core samples
-
由于木材是复杂的天然物,属于散射介质,采集光谱时需要用漫反射光谱分析样品,相对于透射光谱测量方式要更加复杂[15]。样品的可见/近红外光谱还会存在光谱基线偏移、高频噪音、斜坡背景等偏差,影响建模的准确性,使得可见/近红外光谱的分析更加困难。所以利用可见/近红外光谱建模时,需要对光谱进行预处理[16]。
可见/近红外光谱预处理常用的方式就是数字滤波和导数处理。目前常用的数字滤波为平滑处理,光谱平滑可以降低噪音,一定程度上提升信噪比,但过度平滑会使光谱失真。最常用的平滑方式为移动窗口最小二乘多项式平滑(Savitzky-Golay smoothing,S-G平滑)。背景中的基线偏移和光谱旋转可以通过对光谱求导处理进行校正,但是求导的过程中会放大光谱的噪音。如果原始光谱噪音比较大,则不适合直接对光谱进行求导处理。
本研究主要使用了导数和平滑2种光谱预处理方法。考察了原始光谱(raw spectra)、S-G平滑、一阶导数(first derivative,1st Der),二阶导数(second derivative,2nd Der),三阶导数(third derivative,3rd Der),对数(lg),Norris一阶导数滤波(Norris 1st derivative filter),Norris二阶导数滤波(Norris 2nd derivative filter)及组合等11种光谱预处理方法对分类建模预测效果的比较。
-
采用距离法建立识别模型。每个树种采集50个光谱,用SNEE[17]提出的新序贯法(the DUPLEX method)抽取其中30个样品光谱作为校正集,以表征此样品标准光谱。剩余20个样品光谱作为验证集,以验证此方法的可靠性。首先利用每个树种的30个校正集光谱,计算出该树种的平均光谱和标准偏差光谱。
设第q类树种校正集光谱数据矩阵为qW30, n(光谱变量序数j=1, 2, …, n;类序数q=1, 2, …, 14),qwij为qW30, n中的元素(样本序数i=1, 2, …, 30)。第q类树种的平均光谱数据矩阵为qA1, n,$ ^\mathit{q}{\mathit{a}_\mathit{j}}{\rm{ = }}\frac{1}{{30}}\sum\limits_{i = 1}^{30} {^q{w_{ij}}} $为qA1, n中的元素。第q类树种的标准偏差光谱数据矩阵为qS1, n, $ ^\mathit{q}{\mathit{S}_\mathit{j}}{\rm{ = }}\sqrt {\frac{1}{{29}}\sum\limits_{i = 1}^{30} {\left( {^q{w_{ij}}{-^\mathit{q}}{\mathit{a}_\mathit{j}}} \right)^2} } $。对于验证集中每个光谱数据(x1, x2, Λ, xn),首先依次减去14个样品的平均光谱,再除以相对应的标准偏差光谱,得到14条新的光谱。第q条新光谱数据波长上的第j个点对应的数据为(xj-qaj)/qsj,统计此时本类别校正集的内部交互验证的所有新光谱数据,确定阈值。阈值取大于所有新光谱数据的整数值,本研究阈值为3。统计该光谱数据矩阵中所有波长上的点对应的数据超过设定阈值的个数占所有波长上的点的百分比,即为匹配值。该匹配值是一个匹配程度的表示,为0~100%的百分数,0表示最优匹配。未知样本匹配类别为14个类别中匹配值最小,且小于该类别样本校正集内部交互验证的最大匹配值的标准样品的树种类别。若未知样本匹配值大于14个树种校正集样本的内部交互验证的最大匹配值,则此未知样本判别不稳定。
1.1. 样品采集与制备
1.2. 光谱采集
1.3. 光谱预处理
1.4. 识别方法与原理
-
导数处理的实质是将某一波段对应的反射值转变成该波段曲线的切线的斜率,原始光谱波峰与波谷值经过一阶导数处理后为0。所以导数处理可以凸显原始光谱波峰与波谷的位置,同时可以减小光谱的基线偏移偏差。从表 2还可以看出:一阶导数处理后识别准确率较高,识别准确率可达96.79%。而二阶导数与三阶导数对识别准确率的提升没有一阶导数效果明显,识别准确率分别为78.57%和75.00%。图 2以榆树平均光谱为例,可以看出:导数能够消除光谱的基线偏移的同时会增大噪声,特别是高阶导数的处理效果反而差强人意。
识别效果 原始光谱/% 一阶导数/% 二阶导数/% 三阶导数/% 校正集准确率 35.95 96.43 77.62 76.19 验证集准确率 35.71 96.79 78.57 75.00 Table 2. Predicted results after different derivative processing

Figure 2. Average spectrum of elm after derivative processing
-
S-G平滑即移动窗口最小二乘多项式平滑,这种平滑方式有2个参数,平滑点数n(一般为大于1的奇数)和拟合的多项式次数m。对于某一点的处理就是利用该点以及其前后(n-1)/2点,共n个点进行m次多项式的最小二乘拟合。
本研究对700个样品的原始光谱进行各参数的S-G平滑处理,其中平滑点数为3~51点,多项式次数为1~6次,共150种不同的组合。准确率为总准确率,包括校正集的内部交叉验证的准确率和验证集的预测准确率。S-G平滑滤波能降低光谱的噪音,但不会改变光谱的波形(在平滑波长小于半峰宽的情况下)。
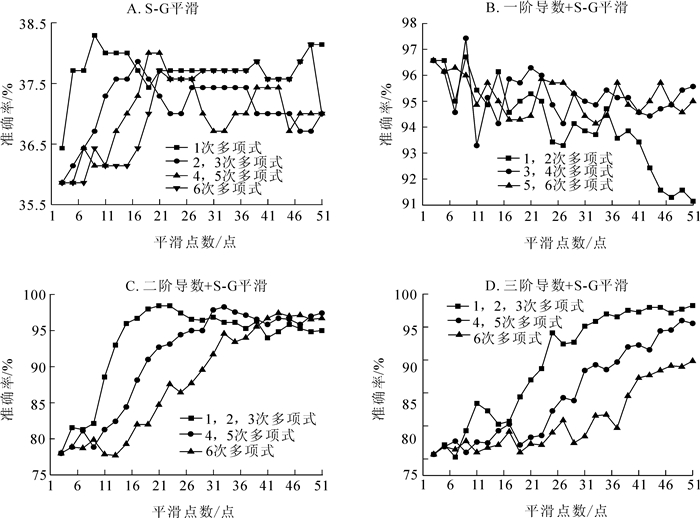
由图 3可知:仅进行S-G平滑处理时,对模型识别准确率的提高效果微乎其微。一阶导数光谱的各参数S-G平滑的效果都很好。其中一阶导数与3次和4次多项式9点S-G平滑的效果最好,误判个数低至7个,准确率高达97.43%。二阶导数和三阶导数处理后的低点数S-G平滑的预测效果略差,识别准确率低于80%。但是随着平滑点数的增多,准确率也不断提高,最终识别准确率稳定在90%以上,其中二阶导数配合1次、2次和3次多项式与21点、23点平滑和三阶导数配合1次、2次和3次多项式与51点平滑的误判个数低至5个,识别准确率高达98.42%。

Figure 3. Different predicted results for 4 spectral pretreatment methods (A)S-G soomthing (B)1st+S-G soomthing (C)2nd+S-G soomthing (D)3rd+S-G soomthing
随着平滑点数在一定范围内增大,使用低次多项式S-G平滑的效果要好于高次多项式S-G平滑,低次多项式的识别准确率高于高次多项式10%以上,但是随着平滑点数继续增大,由于多项式次数和平滑点数开始逐渐匹配,这种差异慢慢减小,识别准确率都在95%以上,且不同多项式之间的差异小于1%。说明多项式次数和平滑点数要“门当户对”才能达到最好的预测效果,不恰当的参数搭配还会使模型的预测准确率降低。同时,随着导数处理的阶数增大,例如三阶导数处理时,达到最好预测效果所需要的S-G平滑点数也增大,说明高阶导数需要配合大点数S-G平滑使用。
-
Norris导数滤波是“近红外之父”NORRIS提出的一种光谱预处理方法。这种方法类似于移动窗口平均和卷积函数求导,但是在窗口段长之间加入了段间距[18],同S-G平滑,窗口段长为1~51内的奇数,点数过高会使覆盖波峰导致光谱失真,大点数设置将失去平滑意义。当段长设置为3时,则段内每个数据点经过滤波变成中心点和两边的点的平均值。段间距为2个连续窗口段长之间的距离,为0~20的自然数,增大段间距可以增强被宽波段重叠的陡峭波段,大点数的间距将影响平滑效果。当段间距设置为3时,则2个连续段长之间的间距为3个波长上的点。S-G平滑滤波对于某一平滑点数,其第1个中心点前的n个点和最后1个中心点的后n个点不能使用S-G平滑方法处理,使用Norris导数滤波可以克服这个问题。
本研究对700个样品的原始光谱进行各参数的Norris导数滤波,其中段长为1~51,段间距为0~20,共546种组合。准确率为总准确率,包括校正集的内部交互验证的准确率和验证集的预测准确率。
-
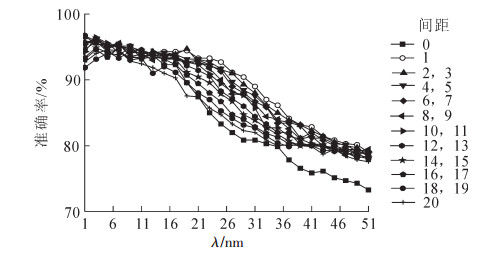
由图 4可知:对于Norris一阶导数滤波,随着段长点数增大,模型的准确率降低,但是当间距为0 nm,段长大于33 nm时识别准确率低于80%。从整体上看,段长大于39 nm的滤波效果都不好,说明Norris一阶导数滤波的段长选择应控制在1~19 nm之间。其中段长为1,段间距为4的一阶导数Norris滤波效果最好,验证集预测误判个数为8个。

Figure 4. 546 predicted results of different 1st+Norris derivative filtering parameter
-
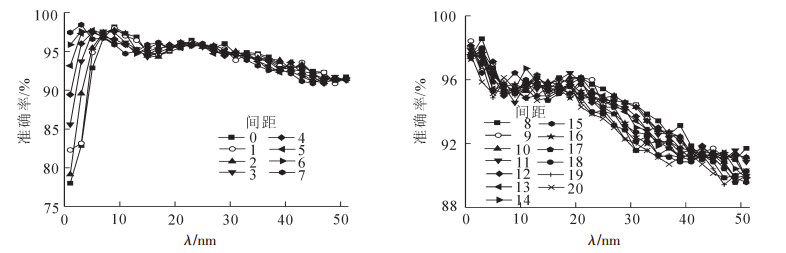
对于Norris二阶导数滤波(图 5),由于间距0~20 nm的各参数的结果不一样,绘制成21个变量的折线图效果不好。现将21种间距的各平滑点数准确率数据进行聚类分析,发现21组数据变化趋势可分为2类:间距0~7 nm和间距8~20 nm,前者为准确率先增大再减小,后者准确率呈减小趋势,如图 5所示。从整体上看,间距为8~20 nm时同Norris一阶导数滤波,随着段长点数变大,识别准确率从98%降低至90%左右。但在间距为0~4 nm时,段长为1 nm与3 nm的Norris导数滤波使模型的准确率低于90%,随着段长点数增大,识别准确率也大幅上升,最高可达98.14%。说明段间距为0~5 nm和6~20 nm的Norris二阶导数滤波的段长最佳选择范围分别为5~15 nm和1~7 nm。其中段长为3 nm和段间距为8 nm的Norris二阶导数滤波效果最好,误判个数低至5个,准确率高达98.21%。

Figure 5. 546 predicted results of different 2nd+Norris derivative filtering parameter
2.1. 基于导数预处理的树种识别

2.2. 基于S-G平滑预处理的树种识别
2.3. 基于Norris导数滤波预处理的树种识别
2.3.1. Norris一阶导数滤波
2.3.2. Norris二阶导数滤波
-
测试了这11种光谱预处理方法对识别模型准确率的影响,这11种方法中若涉及参数选择问题,取准确率最高的参数组合(表 3)。对数(lg),S-G平滑,对数(lg)与S-G平滑等3种处理方式的准确率与原始光谱的准确率一样,说明单纯使用对数(lg)和S-G平滑预处理方式不能提升模型的准确率,原因是对数和平滑处理没有改变原始光谱的波形,只能使光谱更加平滑,不能提高光谱区分度。
预处理方法 校正集准确率/% 校正集正确数/个 校正集误判数/个 验证集准确率/% 验证集正确数/个 验证集误判数/个 总准确率% 原始光谱 35.95 151 269 35.71 100 180 35.86 对数(lg) 35.95 151 269 35.71 100 180 35.86 S-G平滑 35.95 151 269 35.71 100 180 35.86 对数(lg)+S-G平滑 35.95 151 269 35.71 100 180 35.86 一阶导数 96.43 405 15 96.79 271 9 97.70 二阶导数 77.62 326 94 78.57 220 60 78.70 三阶导数 76.19 320 100 75.00 210 70 77.20 S-G一阶导数平滑 97.38 409 11 97.50 273 7 97.43 S-G二阶导数平滑 98.57 414 6 98.21 275 5 98.42 S-G三阶导数平滑 98.33 413 7 98.21 275 5 98.29 Norris一阶导数平滑 97.14 408 12 97.14 272 8 97.14 Norris二阶导数平滑 98.81 415 5 98.21 275 5 98.57 Table 3. Predicted results of 11 processing methods
-
可见/近红外光谱技术能够实现生长锥取样的木材识别。本研究采用距离法识别模型,使用未经任何预处理的光谱识别木材准确率很低。使用S-G平滑处理或对数处理对光谱进行预处理不能提升识别准确率。一阶导数预处理能明显提升木材识别准确率。由于二阶导数和三阶导数会增大光谱的噪音,经过二阶导数或三阶导数预处理的光谱识别准确率为没有一阶导数高。在利用可见/近红外光谱进行树种识别的过程中,二阶导数预处理和三阶导数预处理需与其他预处理方式配合使用,才能达到提升识别模型准确率的效果。
S-G平滑处理能够明显降低二阶导数和三阶导数处理后的光谱的噪音,能够极大程度地提升木材识别模型的准确率。使用Norris导数滤波能够提升木材识别模型的准确率,在最优的参数设置下,Norris导数滤波效果略好于S-G导数平滑,但差异不明显。由于Norris导数滤波的特性,使得它能够处理光谱波长两端的若干个点,而S-G平滑不能对光谱波长两端的若干个点进行处理。所以在选择与导数处理相配合的预处理方式时,Norris导数滤波应为首选。在使用这2种预处理方法时搭配二阶导数的预处理效果最好。
参数的选择对木材识别模型的准确率有一定影响,在使用过程中需要合理选择各项参数。由于Norris导数滤波的可选参数组合要多于S-G平滑,所以在最优参数选择上,Norris导数滤波的工作量要大于S-G平滑。但是通过本试验发现,在控制某一个参数不变,另一个参数递变时识别准确率的变化也呈现出递增/递减的规律,通过合理的参数选择方案可以有效减少最优参数确定的工作量。
 DownLoad:
DownLoad: