







-
森林具有巨大的生态、经济和社会功能,是应对经济全球化发展过程中造成的生态危机和气候变化问题的有效资源。森林资源清查和森林生态保护一直都是各级政府建设的重要内容。实际工作中,护林员通过手机拍摄到的林业现场数据传输回服务器后,可根据林业业务需求快速分类;其分类结果发送到相关管理部门,就可完成对相关事件及时有效的处理。这种森林资源监管模式避免了传统管理手段无法准确及时了解森林现状及动态的问题。要使林业各个管理部门全面配合、相互协调,增强决策支持和加快应急处理,其核心是实现林业业务图像迅速、准确的分类。陈锦标等[1]使用.NET提出了基于分类的林业图像管理信息系统,解决林业图像管理分散、分类混乱、查找困难问题。刘义华等[2]针对林业图像数据的特点,提出了海量数据服务器架设方式和需要解决的关键问题。这些研究的基础是对林业图像进行标注,系统代价高,人工成本也高。本研究中林业业务图像自动分类的理论基础是场景图像分类。场景图像分类是在20世纪90年代末开始兴起的一个研究领域,2006年麻省理工学院首次召开场景理解研讨会后成为了新的研究热点。2005年之前,场景图像分类主要采用基于底层特征(low level features)的方法和基于场景结构的方法;之后则采用基于图像视觉词汇的方法,该类方法由SIVIC等[3]提出视觉词汇的概念,将文本分类中的词袋方法(bag of words, BoW)应用到图像分类中来。之后,由于视觉词汇在图像分类中具有特征表达能力强和简单有效的优点[4],被研究者应用在计算机视觉的图像分类领域[5-12]。词袋方法的核心是提取图像特征构建视觉词汇本。近年来,多采用局部特征用于图像分类,例如,LOWE[13]提出的高效区域检测算法SIFT(scale invariant feature transform)具有图像旋转、尺度缩放、平移保持不变性,该方法在2004年得到完善[14];Dense SIFT即密集SIFT,是在SIFT基础上发展而来的一种算法,相比传统SIFT特征后者具有实时性好、表达能力强的优点。本研究针对林业业务图像数据的特点,利用Dense SIFT提取图像中的业务信息,构建合理的视觉词汇本,描述林业业务图像;根据林业业务管理需求,联合直方图正交核的支持向量机对图像自动分类,并将各类信息传递至各职能管理,从而实现快速、及时、准确、有效的管理。
HTML
-
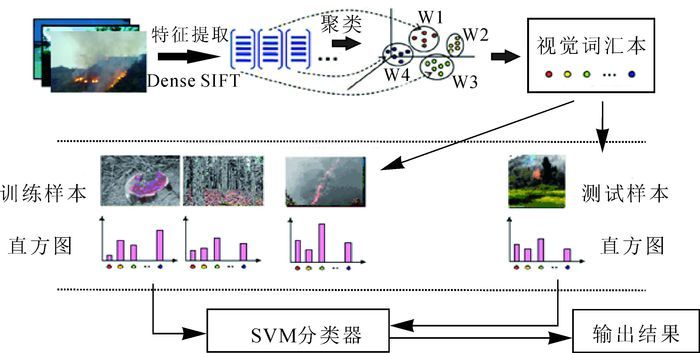
将BoW模型应用于图像分类时,可将图像看作为一个文档,提取的与位置信息无关的关键特征看作为文本中的单词,称作“视觉词汇”;视觉词汇的集合称为“视觉词汇本”。利用“视觉词汇本”表示每幅图像即可完成分类。基本步骤可分为3步。① 特征提取:使用Dense SIFT算法提取林业业务图像的特征,用128维向量表示。② 生成视觉词汇本:所有的特征向量利用K-means聚类算法构造视觉词汇本[4],统计视觉词汇本的词汇在图像中出现的次数,用1个k维直方图向量表示图像。③ 分类器设计:以图像的直方图向量和相应的类别标签作为训练数据,训练SVM分类器。④ 分类:对需要分类的图像先利用视觉词汇本的词汇表示为直方图向量,然后利用训练好的SVM分类器进行预测,输出结果。整体算法流程如图 1所示。

Figure 1. Block graph of BoW model
-
LOWE提出的SIFT算法在数字图像的特征描述上应用广泛且成效明显。基于SIFT进行图像特征的提取一般分为4步组成。
-
图像的尺度空间表示是图像在所有尺度下的描述,高斯卷积是表现尺度空间的一种形式。设图像I(x, y),其尺度空间函数为L(x, y, σ),则有:
式(1)中:G为尺度σ下的二维空间高斯函数,其表达式为:
尺度空间建立之后,可用高斯差分函数D(x, y, σ)为关键点的定位,其表达式为:
式(3)中:k表示层级,是一个常量。
-
关键点存在于图像边缘的高斯差分极值点处,因此,关键点确定的主要问题就是对满足要求的高斯差分函数极值点的计算。为了寻找尺度空间的极值点,每个像素点和所有的相邻点进行比较,当大于(或小于)图像空间和尺度空间的所有相邻点时,为极值点。对尺度空间函数L进行曲线拟合以精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点,增强匹配稳定性,提高抗噪声性能。
-
关键点方向可利用关键点邻域像素的梯度直方图的分布特性进行赋值。首先,计算每个关键点的梯度幅值m(x, y)和方向θ(x, y):
式(4)和式(5)中:L为尺度空间函数。然后,生成梯度直方图,其横轴是梯度方向角,纵轴是梯度方向角对应的梯度幅值累加,直方图的峰值即为该关键点邻域梯度的主方向。
-
以特征点为中心,将坐标轴旋转为关键点的主方向。在关键点周围取16 × 16的邻域像素,并划分为4 × 4的子区域,计算每个子区域的梯度直方图。梯度直方图横轴为8个方向区间,纵轴是每个方向梯度的幅值累加,形成一个具有8个方向梯度强度信息的种子点。每个关键点采用4 × 4个种子点,形成128维的特征向量。此时SIFT特征向量具有尺度、旋转不变性,将特征向量进行归一化,去除光照变化的影响。以数据库中森林火灾类图像为例,图 2A为原图,图 2B为SIFT提取的特征效果图,图 2C为Dense SIFT提取的特征效果图。

Figure 2. Original forest fire image(A) and its SIFT effect image(B) and its Dense SIFT effect image (C)
Dense SIFT在SIFT基础上进行了改进,在目标分类和场景分类有重要的应用。Dense SIFT的原理是将目标区域先划分成大小相同的矩形区,分别计算每一块矩形区的SIFT特征,再对各矩形区的Dense SIFT特征中心釆样并建模,度量不同矩形区间的差异。对图像集的Dense SIFT特征的提取步骤为① 在图像上设定密集采样网格,网格上的交叉点作为特征提取点,以16 × 16像素大小的窗口进行固定采样;② 以8像素的步长自左向右、从上到下在图像上提取SIFT特征描述子。
-
通过以上特征提取算法提取到图像库中训练图像的局部特征,并把所有特征向量集合在一起,构成特征库。利用K-means聚类将特征库中距离相近的划分到同一个聚类类别,聚类数目K∈[200, 1 000],这些聚类中心即为视觉词汇本。所有特征点根据聚拢程度分布到128维坐标系上,分成M类,其中每一个点绝对包含在其中一类中。再以每一类的重心点(或均值点)C为代表点,得到M(C1,C2,…,CK),生成词汇本。计算Dense SIFT特征向量与聚类中心(视觉词汇)的距离,找出距离它最近的聚类中心,然后做词频统计,即统计每个视觉词汇在图像的出现次数。用视觉词汇的直方图向量(K维的向量)表示图像,即为BoW描述向量。图 3给出的是图 2中森林火灾类的一幅图像的直方图。

Figure 3. Histogram of an forest fire image
-
支持向量机(SVM, support vector machine)是由CORTES和VAPNIK在1995年首先提出的,被广泛应用于模式识别、分类等领域,能够比较好地解决高维向量、非线性等问题[15-16],在解决小样本问题上也有比较好的优势。本研究以BoW模型的描述向量数据为训练样本,并赋予相应的标签后训练SVM分类器。
SVM中选择不同的核函数得到不同的支持向量机算法。本研究采用3类核函数。多项式核函数(Poly):
径向基核函数(RBF):
多层感知器核函数(Sigmoid):
由于林业业务图像分类多为非线性分类,因此使用直方图正交核函数(histogram intersection kernel,又称pyramid match kernel)[17],用来对特征构成的直方图进行相似度匹配。
假设2个直方图为x=[x(1), x(2), …, x(n)],y=[y(1), y(2), …, y(n)],则直方图正交核可定义为:
并且存在一个映射φ,能够将任意直方图x映射为一个在高维特征空间φ中的向量φ(x):
通过这个非线性映射φ,直方图近似等价于特征空间φ中的内积。
1.1. 图像特征提取和表示
1.1.1. 建立尺度空间并检测极值点
1.1.2. 确定关键点位置
1.1.3. 确定关键点方向
1.1.4. 确定关键点描述子

1.2. 视觉词汇本创建

1.3. 支持向量机(SVM)分类
-
我们就Dense SIFT特征提取BoW模型和SVM分类器的林业业务图像分类算法进行了仿真实验。实验的硬件平台如下:Intel® Core(TM),i3-3240 CPU@3.40GHz。SVM采用台湾大学CHANG等[18]的LibSVM工具箱。为了验证效果,我们建立了林业业务图像数据集,目前收录了3类林业业务图像:森林火灾、非法采伐和森林病虫害,分别由森林防火指挥部、森林公安和林业有害生物防治检疫局处理。具体实验中,选取60幅·种-1,共计180幅图像作为研究对象;以40幅·种-1作训练样本,20幅·种-1作测试样本。将得到的林业业务原始图像按比例尺截取子区域,缩放至240×240像素统一大小。图 4给出了3类林业业务图像的部分样本。

Figure 4. Data set sample demo of three kinds of forest image
-
构建视觉直方图后,可以用它表示图像中视觉词汇出现的频次了。首先,将训练图像按照BoW描述向量和相应的类别标签通过支持向量机SVM分类器进行训练。然后,将待分类图像使用相同的方法进行Dense SIFT特征提取后用BoW模型进行描述,并采用训练好的分类器进行分类。SVM采用的核函数分别采用上述多项式核函数(Poly),径向基核函数(RBF),多层感知器核函数(Sigmoid)以及直方图交叉核,最后得到各类林业业务图像的分类结果(表 1)。
核函数 森林火灾/% 非法采伐/% 森林病虫害/% 平均识别率/% 多项式核函数 80.0 85.0 75.0 80.0 径向基核函数 85.0 85.0 80.0 83.3 多层感知器核函数 80.0 80.0 75.0 78.3 直方图交叉核函数 85.0 90.0 85.0 86.7 Table 1. Recognition comparison results of three kinds of forestry image with different kernel functions
由表 1可知:对于此3类林业业务,不同的核函数对数据映射的维度不同,尽管结果有一定的差别,但是平均识别率趋势表现为“非法采伐”>“森林火灾”>“森林病虫害”。该结果与3类业务图像的数据特征一致,分析原因认为“非法采伐”含有大量的被砍伐的树木,特征较为明显,识别率高;“森林火灾”由于火灾现场往往含有火或烟雾等特征,但同时一些图像也含有绿叶树木,其识别率次之;“森林病虫害”识别率低是因为病虫害的种类和数量较多,病因与害虫特征表现差异也较大。除Sigmoid核函数内核外,其余的内核平均识别率都达到80%以上,特别是使用直方图正交核进行分类所得到的平均识别率最高,达到了86.7%。由于采用直方图正交核对于直方图的比较问题具有较好的效果,因此使用词袋模型的直方图形式描述图像特征,在直方图正交核上得到了最佳识别效果。
-
为了获得SIFT特征和Dense SIFT特征在林业业务图像上的分类效果,我们在相同实验条件下分别采用SIFT和Dense SIFT特征后得到的分类结果进行比较。其中,选用直方图交叉核函数作为SVM内核,分类识别时间包括训练时间和所有测试图像的分类时间,得到结果如表 2所示。
特征 分类识别时间/s 平均识别率/% SIFT特征 95.567 83.3 Dense SIFT特征 60.143 86.7 Table 2. Recognition comparison with different feature in BoW
由表 2可知:在训练数据库和词袋大小相同时,Dense SIFT特征比SIFT有更高的识别率;采用Dense SIFT作特征提取时训练时间和识别时间更短,更适应实时性较高的场合。林业业务图像往往由多个物体类别组合而成,以森林火灾为例,其图像可能会包含树木、天空、火、烟等多种对象,要求描述这类图像的特征应该有丰富的局部信息。选用SIFT特征提取法仅仅提取图像中的关键点,即图像变化较为突出的区域,难以兼顾图像局部和细节信息;使用Dense SIFT特征提取方法会更优,因为用Dense SIFT对整幅图片进行划分不同的子区域,进而对局部特征有了完整的提取,即使对某些文理、色彩等变化比较平缓的区域,也能求出其局部特征。这表明Dense SIFT生成兴趣点的方法在林业业务图像分类领域可以取得比SIFT兴趣点检测方法更好的性能。
-
为验证BoW模型的有效性,在相同实验条件下,将SIFT或Dense SIFT提取的特征数据作为变量输入,选用直方图交叉核函数作为SVM内核,经支持向量机训练和测试分类。得到结果如表 3所示。
特征 分类识别时间/s 平均识别率/% SIFT特征 33.652 48.5 Dense SIFT特征 21.312 52.3 Dense SIFT特征+BoW模型 60.143 86.7 Table 3. Forestry image recognition performance based on different feature
从表 3可知:Dense SIFT特征提取法的识别率要略高于SIFT特征,这与上一个实验结果所得到的结论是一致的,说明Dense SIFT在局部特征的完整提取上有优势;但是单独使用SIFT或Dense SIFT作为特征进行分类的平均识别率均比采用BoW模型方法要低很多,基于SIFT或Dense SIFT特征提取法的BoW模型能将特征根据林业业务图像类进行重新组合,生成更加能反映业务本身特点的直方图特征,可以大大提高图像识别率。

2.1. 不同核函数识别比较
2.2. SIFT和Dense SIFT特征比较
2.3. 不同模型识别性能比较
-
本研究提出了一种基于Dense SIFT特征的BoW模型,联合直方图正交核的支持向量机对林业业务图像进行自动分类。以收集到的林业业务图像数据集为对象进行实验,结论如下:① 本研究以3类林业业务图像的识别为例,验证发现BoW模型应用于林业业务图像分类可以取得比较好的识别效果。增加新的业务类别时,只要选择足够数量的新增类别的训练样本,重新建立“视觉词汇本”即可。② SIFT和Dense SIFT都能有效地提取到林业业务图像的识别特征;就对图像局部特征完整提取的效果而言,Dense SIFT特征提取法比SIFT在对林业业务图像分类上更有优势。利用BoW模型对特征进行组合,产生的直方图特征更能反映林业业务本身特点,因而识别的准确率得到了极大提高。③ 采用SVM对林业业务图像进行分类时,应用不同的核函数对最后的识别率会产生较大的影响。由于BoW模型使用直方图描述图像的特征,直方图正交核能更好地处理直方图的比较问题,故能取得最佳的识别效果。
综上所述,基于Dense SIFT的BoW模型方法为林业业务图像自动识别研究提供了一种重要思路。该问题的研究与应用有助于中国对森林资源监管模式的创新与实践,有利于加强林业各个管理部门配合,相互协调,增强决策支持和应急处理能力,进而为实现森林的快速、有效、及时的现代化管理打下基础。
 DownLoad:
DownLoad: