






-
近年来,全球二氧化碳排放量逐年增加,对全球气候和生物多样性造成重大影响。森林作为陆地生态系统的主体,发挥其碳汇作用是中国实现碳达峰和碳中和愿景的重要路径[1−2]。林木生物量是估算森林生态系统碳汇能力的基础数据[3],通过全称重法直接获取林木生物量的工作量极大[4],而且大量伐木会破坏森林生态系统。模型法估算林木生物量不仅效率高而且精度满足需求,因此被广泛使用[5]。模型估算法通过建立林木易测因子(如胸径、树高、冠幅)与树木各组分(干、枝、叶、根等)干质量之间的方程,达到用树木易测因子估算不易测因子(各组分生物量)的目的[6]。
相对生长模型是用指数或对数关系反映林木各组分之间按比例协调增长的模型[7]。根据林木各组分之间的相对生长关系建立的恒定异速生长比(constant allometric ratio,CAR)模型在林木生物量估算时被广泛使用。RUARK等[8]认为:CAR模型未考虑林木各组分之间相对生长率随林木大小的变化有可能不是一个常数,进而提出含可变相对生长率的可变异速生长比(variable allometric ratio,VAR)模型。这2种模型中,虽然VAR模型参数相对较多,但能反映异速的协调关系,而且从理论上来说不同大小的树木在竞争和获取各种资源时的能力是不同的,因此其异速关系不是固定的。从这方面看,VAR模型较CAR模型更符合理论实际。张静菲[9]在妙峰山侧柏Platycladus orientali生物量模型研究中对比了这2种模型,结果表明:VAR模型的灵活性和拟合性要优于CAR模型,而CAR模型检验时表现更优。李海奎等[10]研究表明:这2种模型的优劣在不同树种间存在差异,马尾松Pinus massoniana以VAR模型较优,而落叶松Larix spp.则以CAR模型较好,且在建模样本和验证样本中表现也不一致。邱扬等[11]对油松P. tabulaeformis生物量的研究显示:VAR模型优于CAR模型。关于这2个模型的评价国内外学者的研究很多,但结果不尽相同。
兴安落叶松Larix gmelinii是中国北方主要用材树种,面积和蓄积量分别占中国寒温带有林地面积和蓄积量的55%和75%。研究兴安落叶松单木生物量模型对北方碳汇量估计具有重要意义。本研究以大兴安岭地区的兴安落叶松为研究对象,采用非线性似乎不相关回归法,构建2种不同的林木相对生长模型,并对比择优,对测定兴安落叶松单木生物量,以及兴安落叶松天然林生态系统的产量结构和物质循环规律有着十分重要的意义。
-
采样地点为大兴安岭地区塔河林业局盘古林场(52°41′57″N,123°51′57″E)。该区属大陆性季风气候,年平均气温为−5.0 ℃,林内年积雪期为5个月,深度达40 cm。地貌多为山地丘陵。林场面积为15.2万 hm2,蓄积量为844万 m3,森林覆盖率为88.9%。该区地带性植被是以兴安落叶松林为主的寒温带针叶林,其他主要林型有白桦Betula platyphylla林、樟子松P. sylvestris var. mongolica林、针叶混交林以及针阔混交林等。
-
根据盘古林场2011年二类调查数据,在研究区内兴安落叶松林分布的典型地段布设18块20 m×30 m固定样地。对样地进行每木调查,包括树种、胸径和树高等因子,其中树高数据由Vertex Ⅳ超声波测高器测定(精度0.1 m)。根据调查数据,采用等断面积径级标准木法在每块标准地所在林分中选择优势木、平均木和被压木各1株,即按林木胸径大小排序,将林木分为断面积基本相等的3个径级,分别径级选标准木,由大到小依次为优势木、平均木和被压木。因操作条件等限制,其中2块样地内仅选取优势木和平均木,1块样地仅选取平均木,因此最终共选取50株兴安落叶松样木。样木伐倒后,用皮尺测定伐倒木树高,并将树干按2 m区分成若干段,测定各区分段鲜质量;树冠分3层选取标准枝,并分别称量枝、叶鲜质量;地下部分测定大根(>5 cm)、粗根(>2~5 cm)、细根(≤2 cm)鲜质量。样木树干各区分段、每层枝叶以及3种粗度根系都分别取样,带回室内烘干,测其干质量,推算样木各部分干鲜比、各部分干质量,累计汇总得到树冠生物量、地上生物量及总生物量。研究样地基本概况见表1和图1。
统计量 林分因子 树木因子 平均胸径/cm 平均树高/m 株数密度/(株·hm−2) 胸径/cm 树高/m 总生物量/(kg·株−1) 平均值 11.0 12.1 1 886.6 16.4 14.6 178.5 最大值 14.8 19.6 3 333.3 38.1 26.0 897.2 最小值 7.0 6.7 783.3 6.5 6.1 9.8 极差 7.8 12.9 2 550.0 31.6 19.9 887.4 变异系数/% 19.0 22.9 33.3 44.4 27.9 113.7 Table 1. Forest and trees survey factors of L. gmelinii
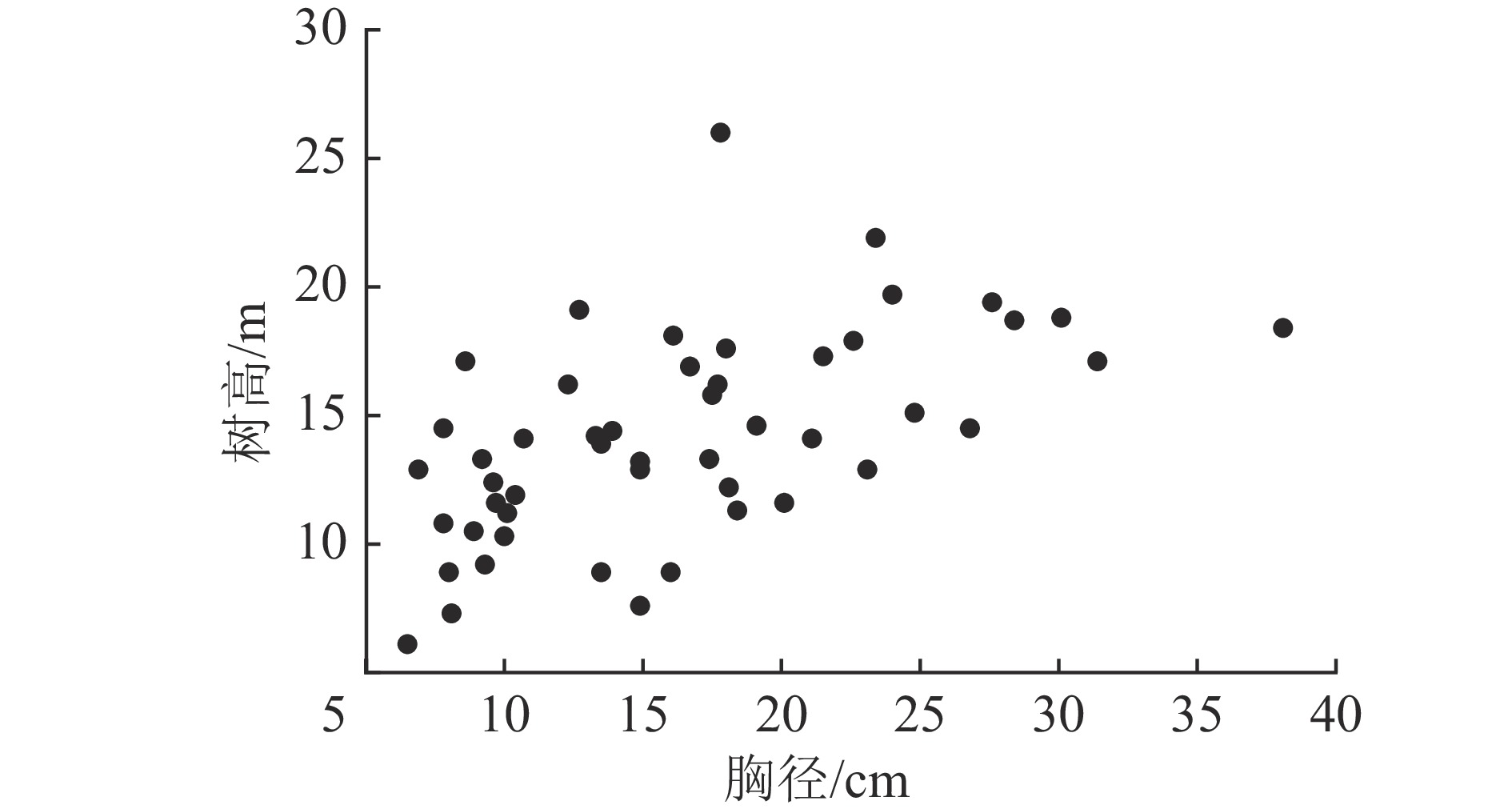
Figure 1. Scatter plot of DBH-tree height distribution of L. gmelinii
-
相对生长法则认为:生物体的2个部分X、Y或全体X和部分Y之间存在下列关系[12]:
X和Y的生长率成比例,比例系数b被称为相对生长系数,其对数形式:
式(1)即CAR模型。该模型未考虑林木各器官之间相对生长率随林木大小的变化,可能不是常数。鉴于此,RUARK等[8]提出了VAR模型(式3),其中X和Y的生长率与X的大小呈线性关系。模型新增的cX通过线性调节相对生长系数b,提供了1个可变的相对生长率。这种相对生长关系方程不再假定随着时间、林木大小的变化相对生长率是1个常数。
其对数形式:
建立生物量模型的主要目的是为了预估,应尽可能选用在立木中比较容易获取的测树因子,而胸径(D)和树高(H)在立木中比较容易获取且数据相对准确,所以本研究以D和D2H为模型变量建立CAR模型和VAR模型。
CAR模型:
VAR模型:
式(5)~(8)中:W为生物量;D为胸径;H为树高;a、b、c为模型参数。
-
在建立生物量模型时,国内外学者普遍先确定各组分生物量的基础模型,然后根据各组分生物量数据分别拟合模型参数,即各组分生物量的估计是独立进行的[13],最终各组分生物量预测值之和与总生物量不相等,生物量间不相容。为解决这一问题,一些学者提出联立方程组的方法[14−16],并选择合适的结构形式建立相容性生物量模型[17]。本研究选用非线性似乎不相关回归法构建聚合型可加性模型。
$ {W}_{\mathrm{t}} $、$ {W}_{\mathrm{a}} $、$ {W}_{\mathrm{r}} $、$ {W}_{\mathrm{s}} $、$ {W}_{\mathrm{b}} $、$ {W}_{\mathrm{f}} $和$ {W}_{\mathrm{c}} $分别代表林木总生物量、地上生物量、树根生物量、树干生物量、树枝生物量、树叶生物量和树冠生物量。以式(9)~(12)为基础模型构建兴安落叶松总生物量及各组分生物量模型,之后按照可加性的定义[18],构造总生物量与各组分生物量的可加性生物量模型。本研究采用聚合型可加性生物量模型,建立的聚合型可加性生物量模型需满足[19]:①各组分生物量之和等于总生物量;②树枝、树叶、树干生物量之和等于地上生物量;③树枝、树叶生物量之和等于树冠生物量。此外,由于生物量存在异方差性,必须选用适当的权函数加权回归或者将模型化为对数形式消除异方差。本研究选用对数转换方式来消除异方差。
CAR-D模型:
CAR-D2H模型:
VAR-D模型:
VAR-D2H模型:
式(9)~(12)中:$ {{\alpha }_{i}^{\mathrm{*}}} $、$ {{b}_{i}^{\mathrm{*}}} $、$ {{c}_{i}^{\mathrm{*}}} $为模型参数;i表示林木各组分;其余变量如前所述。4个模型的树冠生物量、地上部分生物量和总生物量均可表示为:
-
很多学者认为必须利用检验样本检验模型。KOZAK等[20]和曾伟生等[21]认为:单独设置检验样本的交叉验证不必要,建议利用整个样本进行建模。目前刀切法被广泛用于检验模型的预测能力,因此,本研究用全部数据拟合模型,并用调整决定系数($ {R}_{\mathrm{a}}^{2} $)、均方根误差(RMSE)和模拟效率(EF)评价模型拟合效果;采用刀切法检验模型,平均预估误差(MPE)、平均绝对误差(MAE)和预测精度(P,%)评价模型预测能力[22−24]。刀切法主要思路是设N为样本量,用N−1株样木数据建模,预测剩余的单株样木,重复N次后可获得每株样木的生物量刀切法预测值。
-
使用对数转换模型估计林木生物量时,由模型估计值的反对数得到的生物量估计值会存在一个系统偏差,校正系数(CF)可校正此偏差[25]。然而MADGWICK等[26]研究发现:使用校正系数会造成生物量的高估,建议在模型反对数偏差很小时,不进行生物量的校正。
-
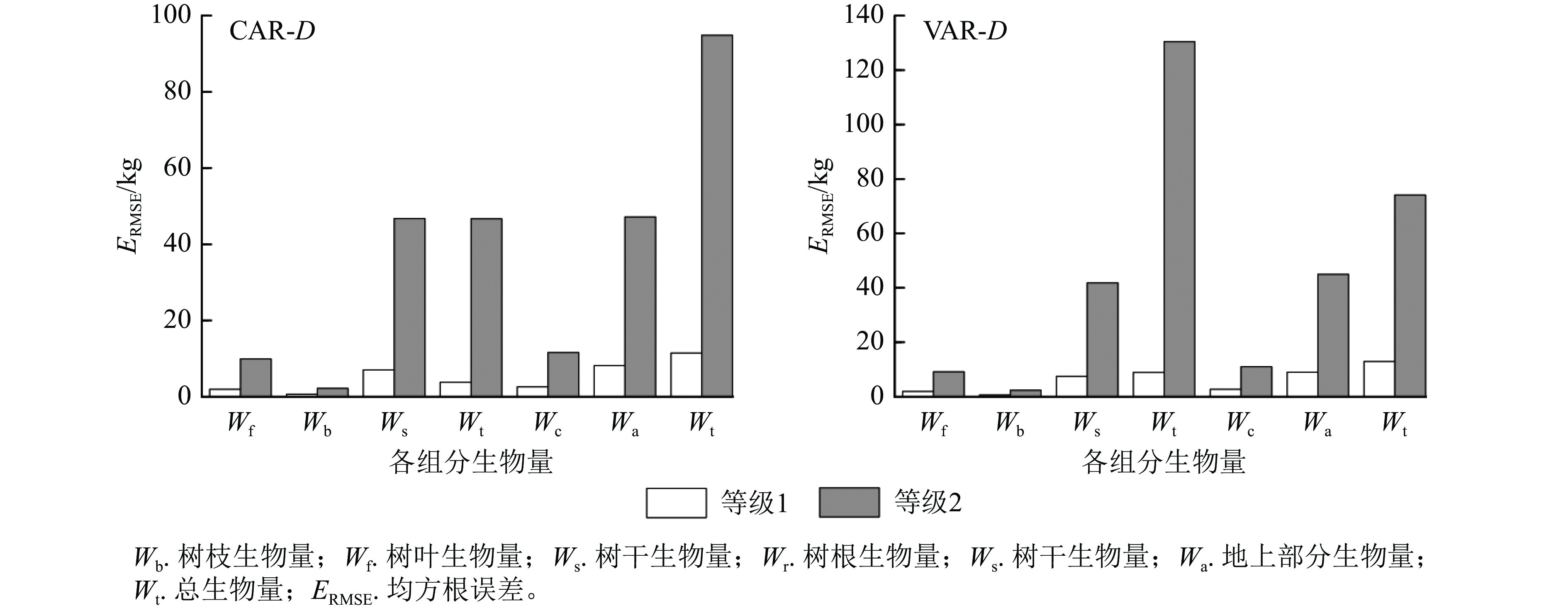
以D为变量,建立CAR和VAR的一元相容性生物量模型。从表2可以看出:兴安落叶松CAR模型的总生物量及各组分生物量模型的调整后决定系数比VAR模型的高0~0.008,平均高0.003;CAR模型的均方根误差除树枝生物量模型外均低于VAR模型,平均低0.005;模拟效率除树枝、树干和树冠生物量外,均是CAR模型值较高,表明从调整后决然定系数、均方根误差和模拟效率3个指标看,CAR一元模型中总生物量及各组分生物量模型优于VAR模型。
组分 模型 参数估计值 拟合优度 校正系数 ${a^*} $ ${b^*} $ $ {c^*}$ 调整后决定系数 均方根误差 模拟效率 树枝生物量 CAR
VAR0.016 5 (0.000 4)
0.009 4 (0.000 4)2.250 7 (0.009 1)
2.587 2 (0.022 0)
−0.021 1 (0.001 2)0.855
0.8550.414
0.4130.858
0.8611.001 7
1.000 0树叶生物量 CAR
VAR0.066 4 (0.004 2)
0.038 6 (0.002 5)1.341 4 (0.023 9)
1.669 5 (0.027 7)
−0.017 8 (0.001 9)0.701
0.6930.387
0.3920.707
0.7011.000 1
1.079 7树干生物量 CAR
VAR0.052 7 (0.001 0)
0.030 6 (0.001 1)2.615 9 (0.007 0)
2.939 7 (0.020 3)
−0.020 2 (0.001 2)0.956
0.9560.250
0.2500.957
0.9431.007 1
1.007 6树根生物量 CAR
VAR0.008 7 (0.001 1)
0.005 0 (0.000 7)2.900 4 (0.044 5)
3.232 4 (0.050 7)
−0.017 0 (0.002 3)0.905
0.8980.419
0.4330.907
0.9021.000 8
1.125 8树冠生物量 CAR
VAR−
−−
−−
−0.849
0.8470.376
0.3790.858
0.8621.001 1
1.000 0地上部分生物量 CAR
VAR−
−−
−−
−0.965
0.9640.214
0.2180.969
0.9701.000 1
1.000 0总生物量 CAR
VAR−
−−
−−
−0.974
0.9720.191
0.1980.977
0.9441.012 7
1.000 5说明:括号内数值为参数标准误。−表示无此项。 Table 2. Parameter estimation, goodness of fit and correction coefficient of two forms of one-dimensional compatible biomass model of L. gmelinii
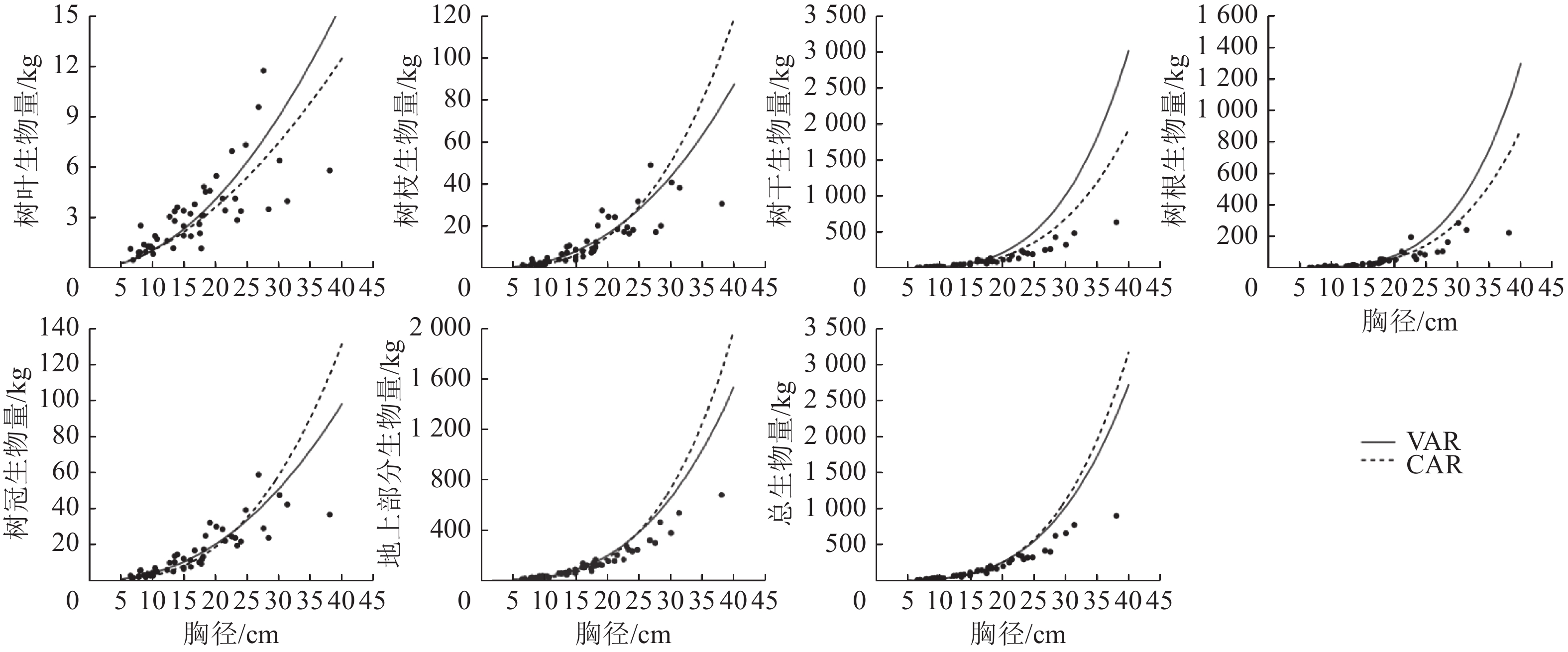
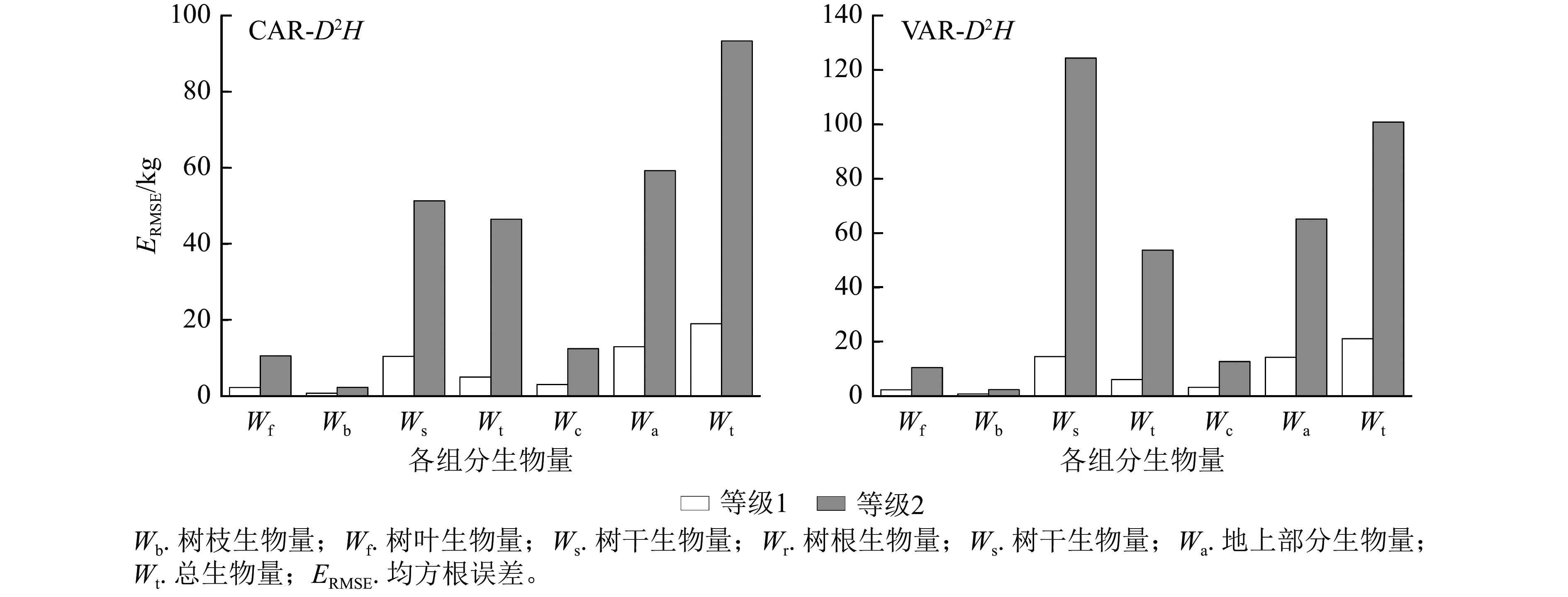
以本研究建立的CAR、VAR模型参数为基础,模拟林木各组分生物量随胸径的变化(图2),并按照林木株数将林木胸径划分为2个等级,其中等级1为小径级(6~14径阶),等级2为大径级(16~32、38径阶,2 cm为1个径阶),绘制2种模型的一元相容性模型对不同胸径等级林木各组分生物量拟合的均方根误差(图3)。可以看出:2种模型对较小径阶林木拟合效果较为一致,随林木胸径进一步增大,拟合差异愈加显著;2种模型对小径阶林木总生物量及各组分生物量的拟合效果更好,小径阶林木的均方根误差明显小于大径阶林木,大径阶林木的均方根误差比小径阶林木平均高4.8倍。
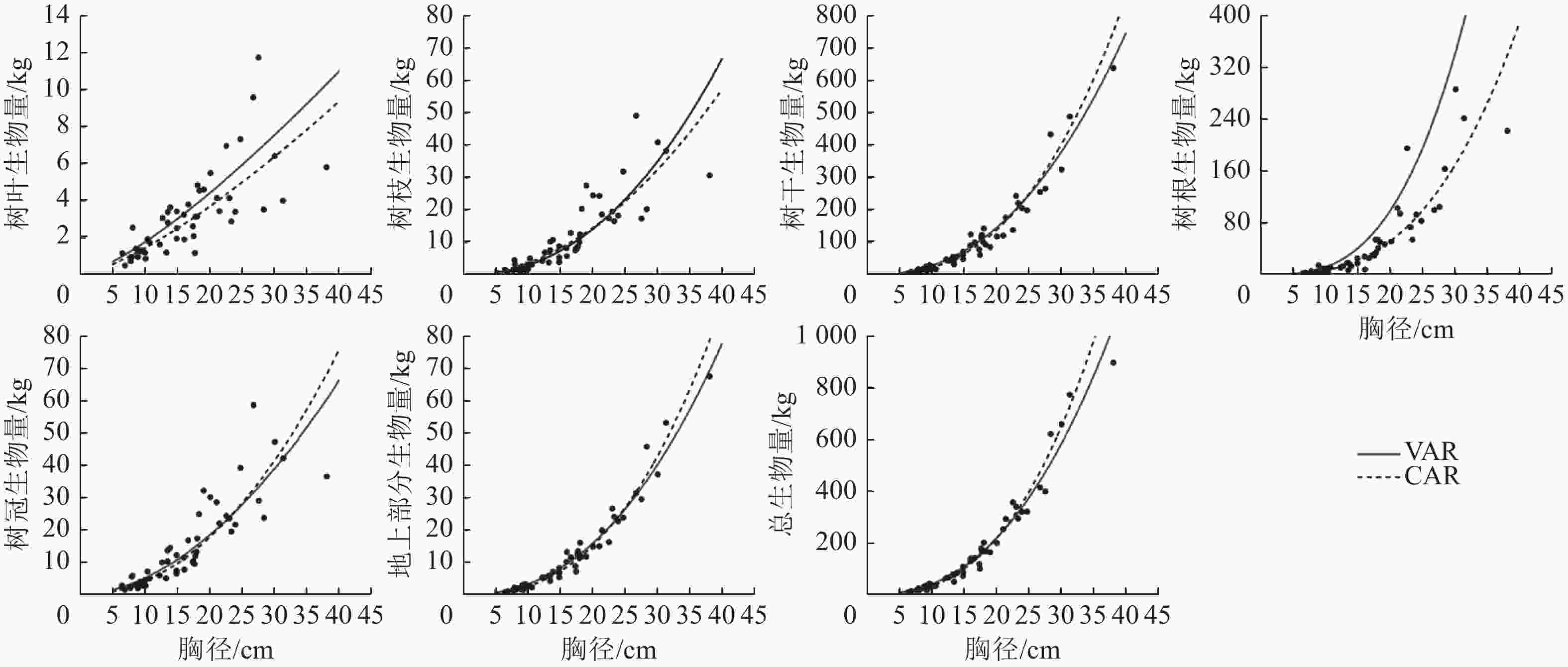
Figure 2. Fitting simulation diagram of the biomass of each part of L. gmelinii by the one-dimensional model of CAR and VAR models
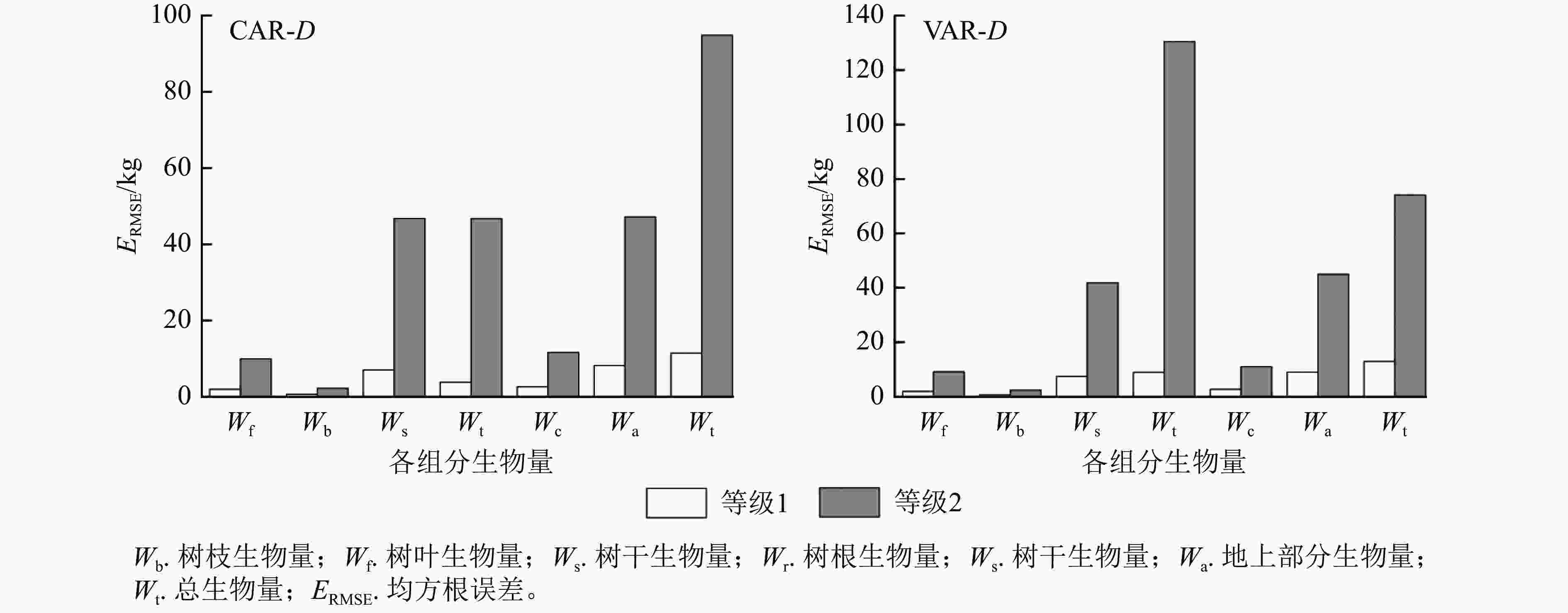
Figure 3. Root mean square error of biomass fitting of each component with different DBH grades by one-dimensional model
-
建立以D2H为变量的2种二元相容性模型,模型参数估计值以及拟合、检验结果见表3。由表3可知:兴安落叶松CAR总生物量及各组分生物量模型的调整后决定系数均大于VAR模型,平均约大0.07;均方根误差均小于VAR模型,平均约小0.090;除树枝和树冠生物量外,CAR模型模拟效率较高或两者相同。表明从调整后决定系数、均方根误差及模拟效果看,CAR二元模型拟合效果优于VAR模型。
组分 模型 参数估计值 拟合优度 校正因子 $a^* $ $b^* $ $c^* $ 调整后决定系数 均方根误差 模拟效率 树枝生物量 CAR
VAR0.005 5 (0.000 2)
0.004 5 (0.000 2)0.8919 (0.004 2)0.9229 (0.006 1)−0.000 007 (0.000 0) 0.761
0.7570.531
0.5340.766
0.7671.001 3
1.000 8树叶生物量 CAR
VAR0.041 5 (0.003 5)
0.034 1 (0.003 0)0.5091 (0.010 7)0.5380 (0.011 2)−0.000 005 (0.000 0) 0.589
0.5750.453
0.4600.597
0.5931.000 2
1.041 3树干生物量 CAR
VAR0.010 0 (0.000 2)
0.008 5 (0.000 3)1.0852 (0.002 8)1.1096 (0.004 6)−0.000 005 (0.000 0) 0.942
0.9390.288
0.2950.943
0.9421.005 8
1.051 2树根生物量 CAR
VAR0.001 8 (0.000 3)
0.001 4 (0.000 3)1.1742 (0.019 6)1.2026 (0.023 0)0.000 002 (0.000 0) 0.847
0.8430.530
0.5380.851
0.8491.000 6
1.039 9树冠生物量 CAR
VAR−
−−
−−
−0.746
0.7370.487
0.4960.762
0.7641.001 2
1.001 0地上部分生物量 CAR
VAR−
−−
−−
−0.933
0.9280.296
0.3060.940
0.9401.000 1
1.000 1总生物量 CAR
VAR−
−−
−−
−0.935
0.9280.300
0.3160.944
0.9441.013 5
1.002 8说明:括号内数值为参数标准误。−表示无此项。 Table 3. Parameter estimation, goodness of fit and validation of two forms of two-dimensional compatible biomass model of L. gmelinii
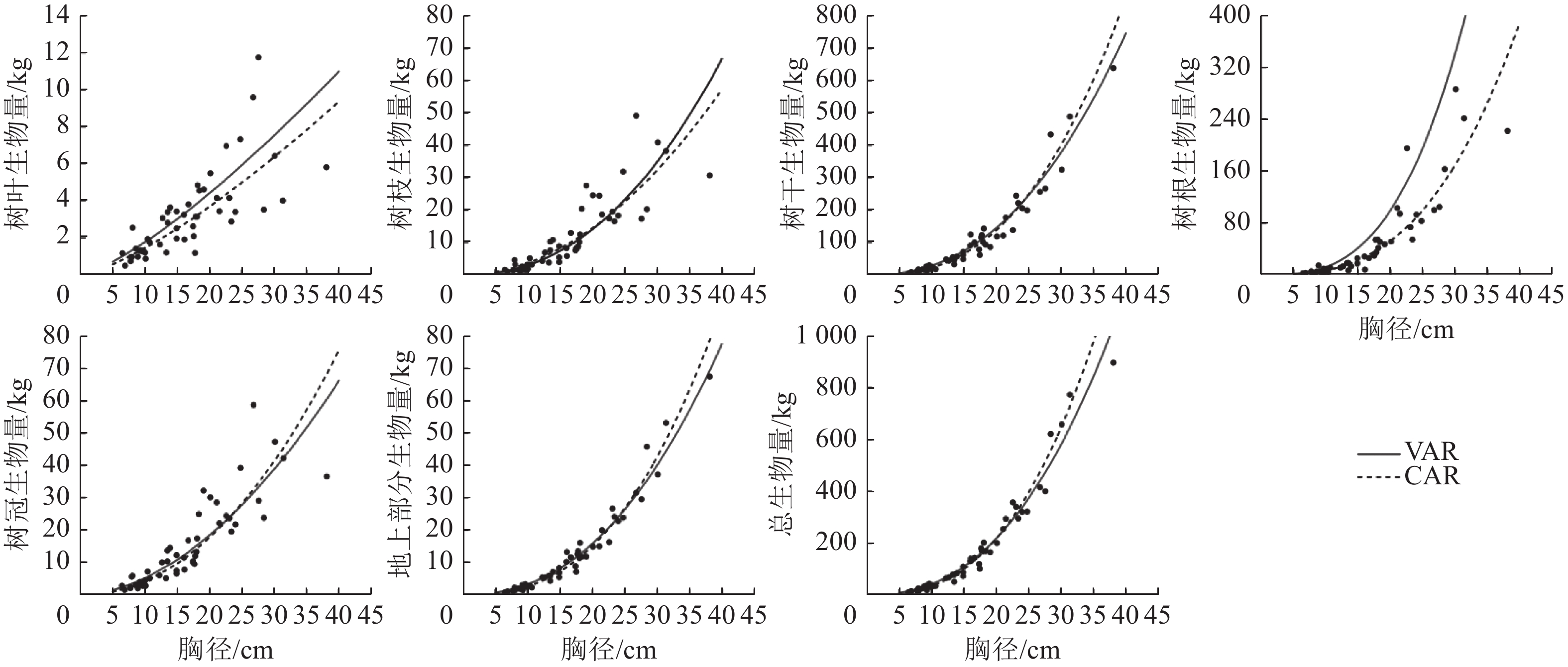
以董灵波等[27]建立的天然兴安落叶松的树高胸径曲线(Wykoff方程)为基础,采用相同方法得到2种模型形式的二元模型对兴安落叶松各组分生物量的拟合结果(图4)及二元模型对不同胸径等级林木各组分生物量拟合的均方根误差(图5)。随林木胸径进一步增大,2种模型的拟合效果都降低。CAR和VAR二元模型对林分总生物量及各组分生物量的拟合中,大径阶林木的均方根误差均明显高于小径阶林木,表明2种二元模型对小径阶林木的拟合效果均优于大径阶林木。此外,2种模型中树枝、树叶和树冠生物量模型的均方根误相对较小,表明模型对这3个组分生物量的拟合误差较小。
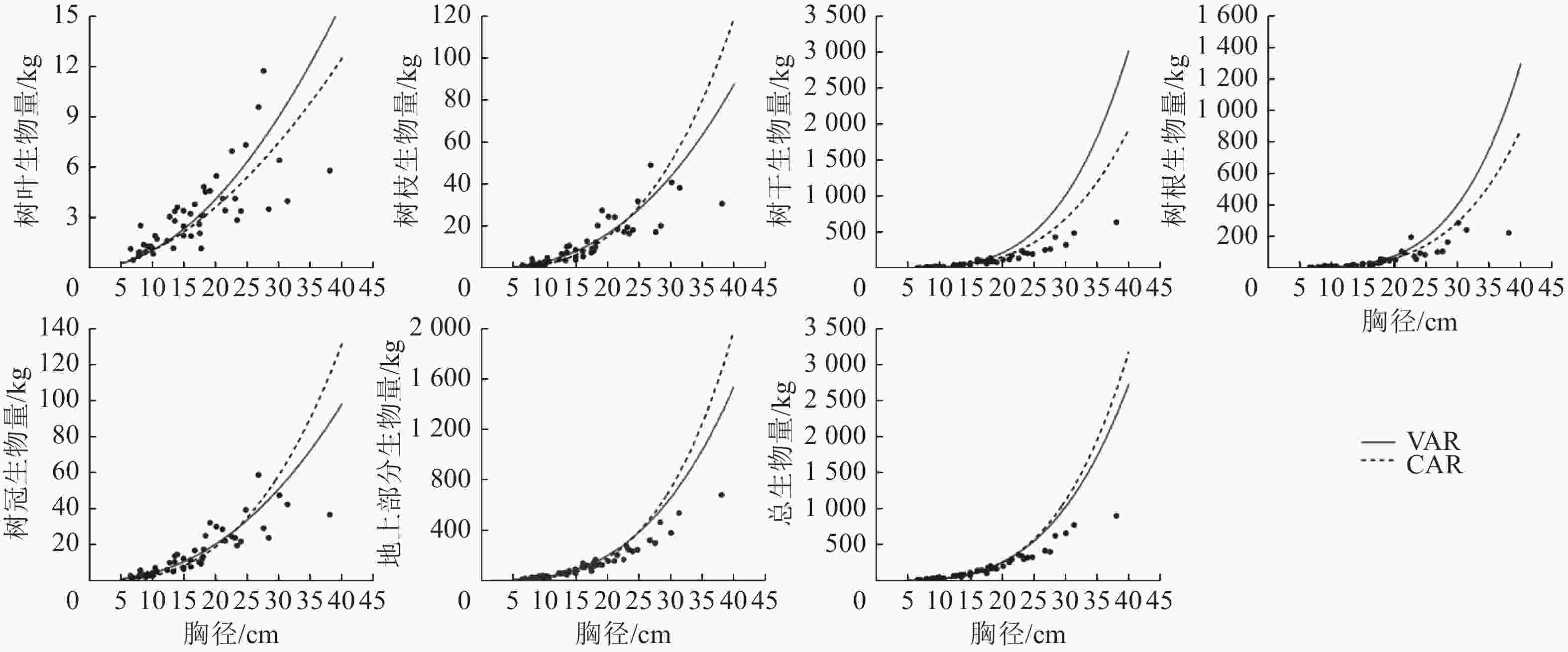
Figure 4. Fitting simulation diagram of the biomass of each part for L. gmelinii by the two-dimensional model of CAR and VAR models
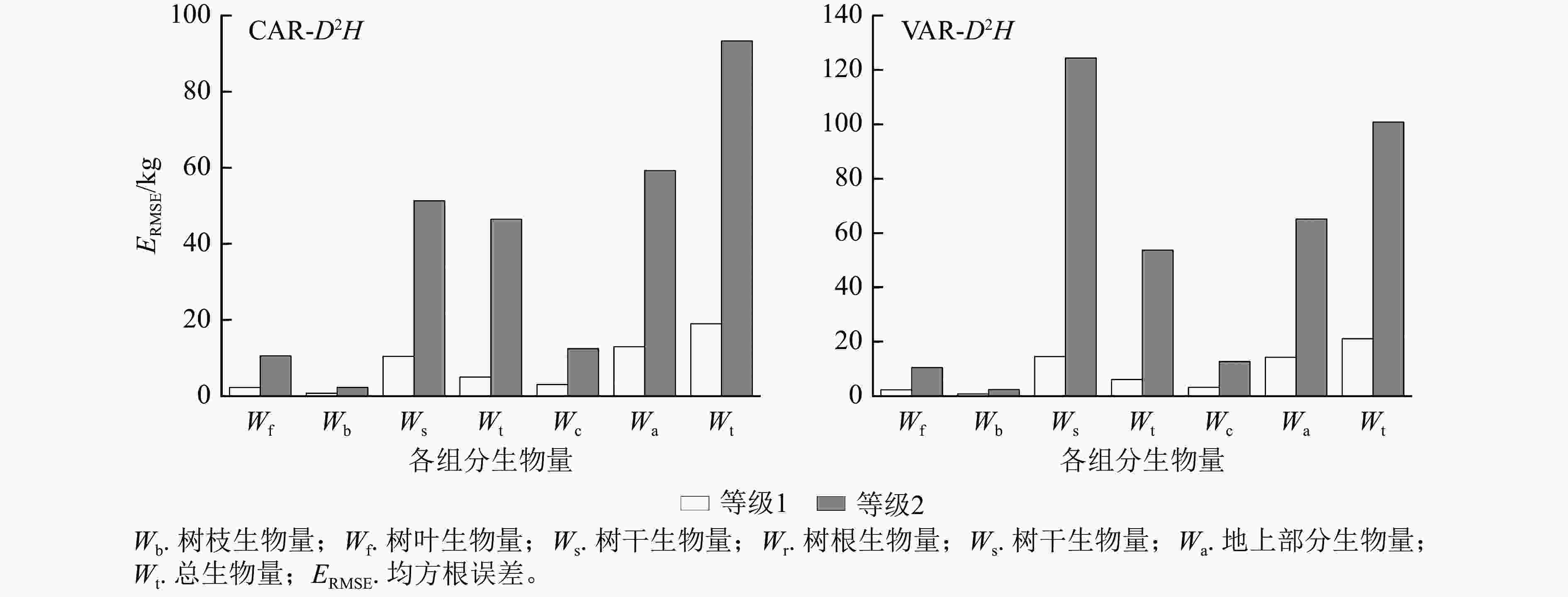
Figure 5. Root mean square error of biomass fitting of each component with different DBH grades by two-dimensional model
-
CAR模型中的树叶、树根和树干模型的平均预估误差的绝对值小于VAR模型,树枝、树冠和总生物量模型的平均预估误差的绝对值大于VAR模型(表4);CAR模型中的树枝、树叶、树根模型的平均绝对误差小于VAR模型,地上部分生物量和总生物量模型的平均绝对误差大于VAR模型;2种模型的各组分生物量模型的预测精度均大于97.6%,且CAR模型的各组分生物量模型预测精度均较高。从检验指标看CAR模型略优于VAR模型。总的来说,CAR模型的一元相容性模型好于VAR模型。
组分 模型 平均预估误差 平均绝对误差 预测精度/% 组分 模型 平均预估误差 平均绝对误差 预测精度/% 树枝生物量 CAR −0.009 0.350 97.90 树冠生物量 CAR 0.006 0.317 97.85 VAR −0.004 0.352 97.87 VAR −0.004 0.317 97.80 树叶生物量 CAR −0.003 0.321 97.90 地上部分生物量 CAR 0.002 0.172 97.80 VAR −0.057 0.327 97.87 VAR −0.002 0.167 97.72 树干生物量 CAR −0.017 0.213 97.90 总生物量 CAR 0.021 0.152 97.75 VAR −0.019 0.213 97.87 VAR 0.002 0.149 97.63 树根生物量 CAR −0.004 0.321 97.90 VAR −0.068 0.337 97.87 Table 4. Test results of two forms of one-dimensional compatible biomass model of L. gmelinii
-
由表5可见:CAR模型中的树叶、树根和地上部分模型检验指标平均预估误差的绝对值小于VAR模型,树枝、树干、树冠和总生物量模型的平均预估误差的绝对值大于VAR模型;CAR模型中林木总生物量及各组分生物量模型检验指标平均绝对误差均小于VAR模型;2种林木各组分生物量模型的预测精度均大于96.9%,且均是CAR模型的各组分生物量模型预测精度更高(表5)。
组分 模型 平均预估误差 平均绝对误差 预测精度/% 组分 模型 平均预估误差 平均绝对误差 预测精度/% 树枝生物量 CAR −0.007 0.469 97.31 树冠生物量 CAR 0.007 0.418 97.25 VAR −0.005 0.474 97.25 VAR 0.006 0.423 9716 树叶生物量 CAR −0.002 0.393 97.31 地上部分生物量 CAR 0.001 0.225 97.19 VAR −0.014 0.401 97.25 VAR 0.002 0.228 97.06 树干生物量 CAR −0.015 0.226 97.31 总生物量 CAR 0.022 0.224 97.13 VAR −0.014 0.230 97.25 VAR 0.010 0.230 96.94 树根生物量 CAR −0.002 0.409 97.31 VAR −0.049 0.415 97.25 Table 5. Test results of two forms of two-dimensional compatible biomass model of L. gmelinii
-
利用模型估算林木生物量具有重要的现实意义。本研究建立的2种林木相对生长模型——CAR模型和VAR模型,在一定程度上都能较好地估算林木生物量。比较而言,CAR模型在拟合优度和预估精度上均优于VAR模型,这与胥辉[28]、姚正阳等[29]的研究结果一致。此外,刘志刚等[30]对华北落叶松L. principis-rupprechtii的研究结果表明:CAR模型对枝和叶生物量的估计是有偏的,而VAR模型的估计基本上无偏,与本研究的结论不一致。可能的原因是这2种模型有各自的适用区域、适用树种,因此,拟合估计不同区域或不同树种林木生物量应该选取不同的模型。本研究中一元模型拟合效果优于二元模型,可能是因为林木总生物量及各组分生物量与D紧密相关,而与D2H的相关性更弱。
本研究中各模型的拟合效果受林木胸径等级影响。林木胸径分为等级1和等级2,这2种模型的一元模型和二元模型对大径阶林木拟合优度普遍低于较小径阶林木。本研究采用均方根误差来衡量模型对大小径级拟合效果的好坏,均方根误差对建模数据集中的偏离程度较大的离散点非常敏感,即使异常离散点非常少,也会引起均方根误差的明显变差。在这2种模型中,大径阶林木与小径阶林木拟合优度差异明显可能是因为数据集中存在异常离散点。一般来说,变量值平均水平越高,其离散程度越大,反之越小,因此,随着林木径阶的增大,生物量的离散程度也随之增加,即大径阶林木更容易出现异常离散点。鉴于数据中34~38径阶的林木只有1株且为38径阶,可能会影响到分级后的拟合效果对比,故剔除38径阶的数据,重新划分胸径等级,其中等级1为小径级(6~14径阶)、等级2为大径级(16~32,2 cm为1个径阶)。结果表明:剔除最大值后,2种模型的拟合效果均仍以小径阶林木为更好,但较剔除前,均方根误差整体呈下降趋势。
本研究林木的平均胸径约为16 cm,26~38径阶的林木只有6株,所建立的模型在理论上应更偏向于适用胸径小于26 cm的林木,对大径阶林木尤其是26径阶以上的林木不太适用。因此,当以本研究所建立的模型参数为基础拟合胸径等级2的林木时,会降低该等级中的大径阶林木的拟合优度,即当数据集较小时,林木的胸径分布会影响所建立模型对不同胸径等级的适合度。二元模型在拟合生物量时,需要通过树高-胸径模型(本研究选用Wykoff方程)推算林木树高,而该模型精度有限,从而进一步引入误差。本研究中的二元模型的拟合优度普遍低于一元模型,可能是此原因所致。此外,本研究根据全部数据建立的模型更适用于小径阶林木,因此或可通过林木胸径分级,建立适用不同径阶大小的模型;或通过进一步优化模型形式,设计出适用于大径阶林木的单木生物量模型,提高拟合精度。许多研究报道,相对生长模型不能很好地拟合所有的观测数据,这一问题在估算大树生物量时尤其突出,说明相对生长模型的适用性有限[31]。今后可从优化初始模型入手,进一步提升模型的预估能力。
-
本研究以兴安落叶松林为研究对象,探讨了CAR和VAR不同相对生长模型预估精度的差异。从模型拟合效果和预测能力来看,一元模型和二元模型均表现为CAR模型优于VAR模型;这2种模型的一元模型和二元模型拟合优度均与林木胸径等级有关,均是小径阶林木的拟合效果更佳;一元模型和二元模型中,树枝、树叶和树冠生物量模型误差均较小,拟合效果更好。总的来说,CAR模型不仅形式上更简单,而且拟合效果和估计精度与VAR相比也更佳。
Accuracy evaluation of 2 allometric biomass models
doi: 10.11833/j.issn.2095-0756.20240512
- Received Date: 2024-08-28
- Accepted Date: 2025-03-03
- Rev Recd Date: 2025-03-01
- Available Online: 2025-11-26
- Publish Date: 2025-11-26
-
Key words:
- Larix gmelinii /
- constant allometric ratio (CAR) model /
- variable allometric ratio (VAR) model /
- single tree biomass
Abstract:
| Citation: | WANG Yi, MEI Xuesong, YUAN Ye, et al. Accuracy evaluation of 2 allometric biomass models[J]. Journal of Zhejiang A&F University, 2025, 42(6): 1122−1131 doi: 10.11833/j.issn.2095-0756.20240512

|
 DownLoad:
DownLoad: